OCR
OCR images, scans और document screenshots से text extract करता है।
Recognition के बाद आप result copy कर सकते हैं, उसे Markdown, PDF या Word के रूप में export कर सकते हैं, या multiple formats को साथ package करके download कर सकते हैं।
OCR क्या कर सकता है
| Feature | Description |
|---|---|
| Image text recognition | Images, screenshots और scans से text extract करता है। |
| Document layout recognition | Tables, formulas, stamps और mixed text-image layouts के लिए बेहतर। |
| Multiple services | Baidu PaddleOCR, Microsoft Azure Vision और Google Vision support करता है। |
| Copy results | Processing के बाद recognized text copy करें। |
| Export files | Markdown, PDF और Word export करें। |
| Batch packaging | Multiple files recognize करने के बाद results को package के रूप में download करें। |
पहले OCR Services Configure करें
खोलें:
text
System Settings -> Other Settings -> OCR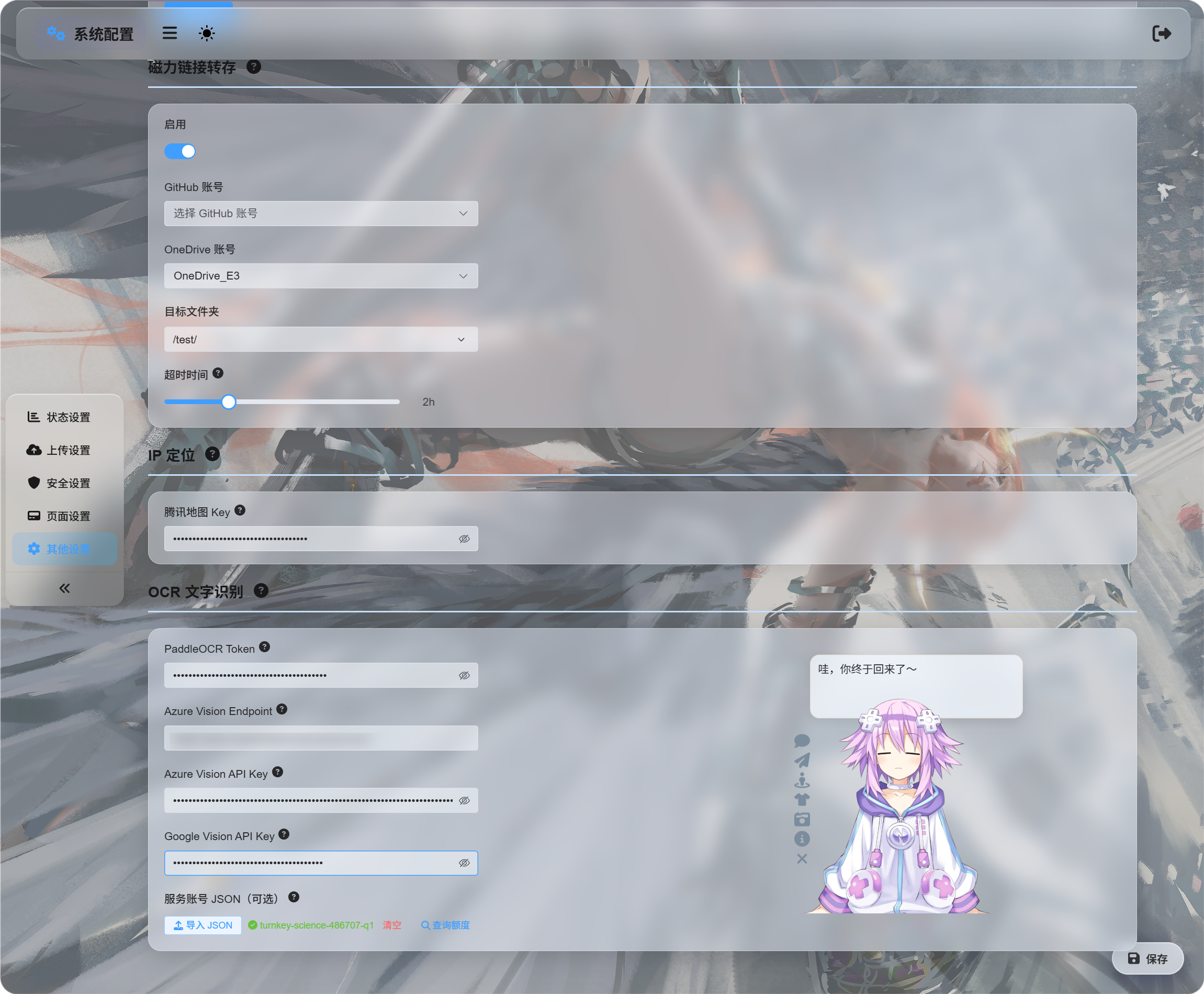
जिन services को इस्तेमाल करना चाहते हैं उनके credentials भरें:
| Service | What To Enter | Best For |
|---|---|---|
| Baidu PaddleOCR | PaddleOCR Token | Recommended first choice। Documents, images, tables और mixed layouts के लिए अच्छा। |
| Microsoft Azure Vision | Azure Vision Endpoint और Azure Vision API Key | अगर आप पहले से Microsoft cloud services इस्तेमाल करते हैं तो useful। |
| Google Vision | Google Vision API Key। Service account JSON केवल quota query के लिए इस्तेमाल होता है। | अगर आप Google Cloud services इस्तेमाल करते हैं तो useful। |
Credentials भरने के बाद save करें।
Initial testing के लिए केवल एक service configure करना काफी है। तीनों की ज़रूरत नहीं।
Google Vision Setup
Google setup के दो हिस्से हैं:
| Goal | Requirement |
|---|---|
| OCR इस्तेमाल करना | Cloud Vision API enable करें, फिर API Key बनाएं। |
| Usage query करना | Service account बनाएं, Monitoring Viewer दें, फिर service account JSON download करें। |
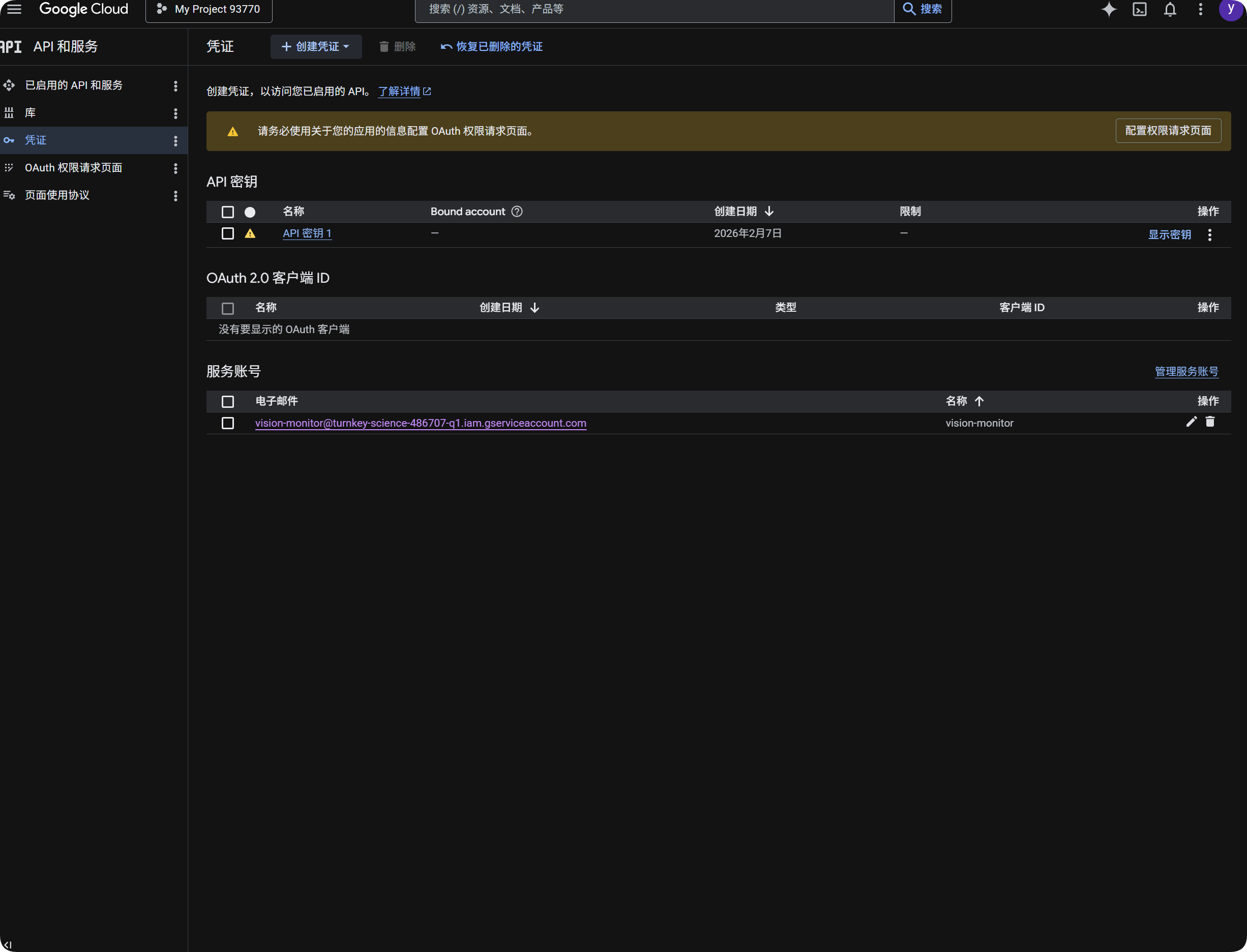
OCR के लिए Google इस्तेमाल करना
- Google Cloud Console खोलें।
APIs & Servicesपर जाएँ।Libraryखोलें,Cloud Vision APIsearch करें और enable करें।Credentialsपर वापस जाएँ।- एक
API Keycreate करें। - API Key खोलकर copy करें।
- ImgBed के
Google Vision API Keyमें paste करें। - Save करें।
इसके बाद OCR dialog में Google Vision चुन सकते हैं।
Google Usage Query करना
Quota query recognition के लिए required नहीं है।
यह केवल roughly दिखाता है कि पिछले 30 दिनों में कितनी Google Vision calls इस्तेमाल हुईं।
- Google Cloud Console में
IAM & Adminखोलें। Service Accountsखोलें।- एक service account बनाएं, जैसे
vision-monitor। - उसे
Monitoring Viewerrole दें। - Service account details खोलें और key create करें।
JSONचुनें।- Generated JSON file download करें।
- ImgBed पर लौटें और service account
JSONके तहत इसे import करें (optional)। - Import successful होने के बाद quota query click करें।
Import के बाद ImgBed service account वाला project name दिखाता है। Usage query करते समय ImgBed Google monitoring data पढ़कर इस महीने का call count दिखाता है।
संक्षेप में:
| Item | Purpose |
|---|---|
Google Vision API Key | OCR recognition करता है। |
Service account JSON | Google Vision calls की usage query करता है। |
Monitoring Viewer role | Service account को usage data पढ़ने देता है। |
Baidu PaddleOCR Token लेना
Baidu PaddleOCR को access token चाहिए।
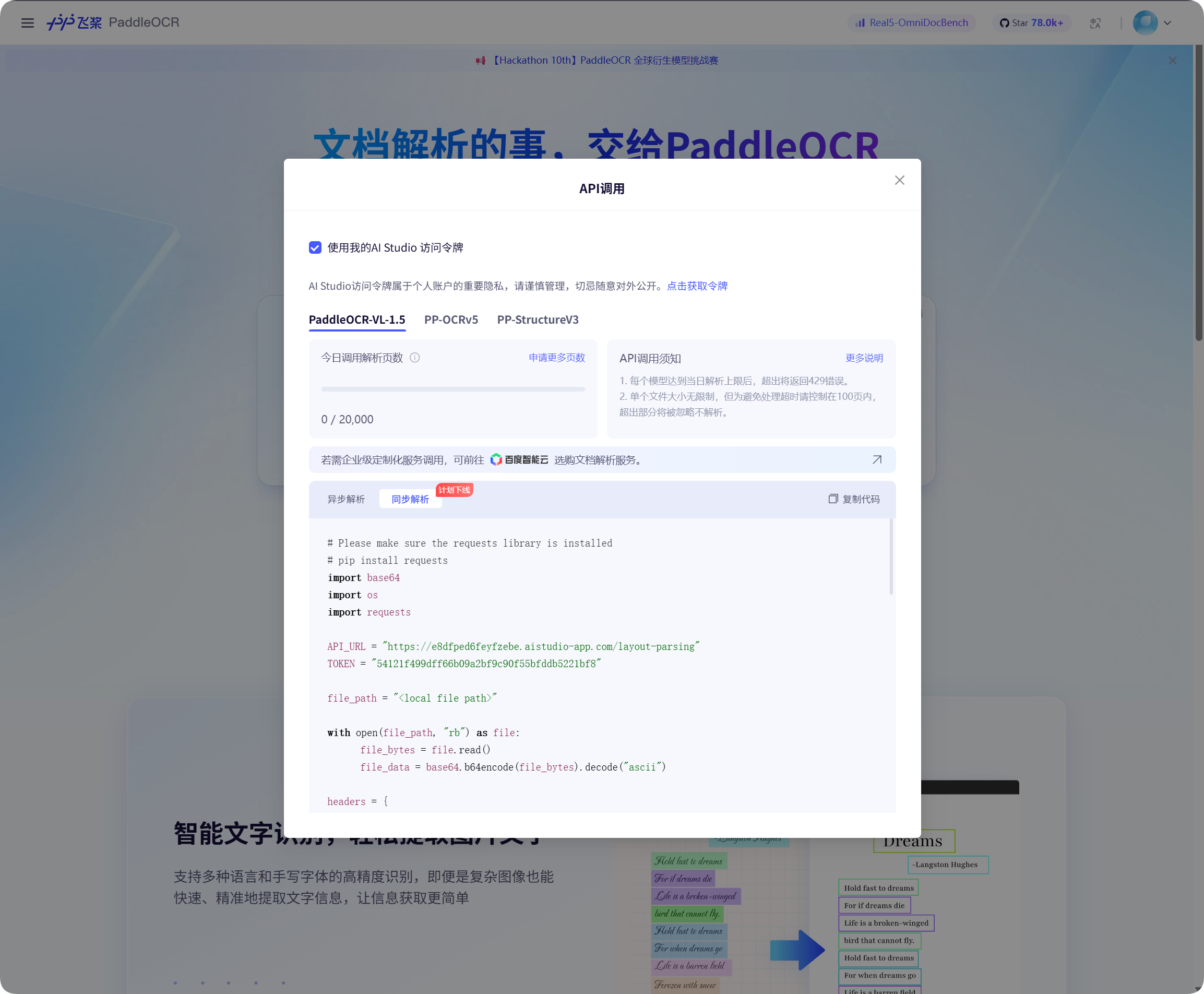
Baidu PaddleOCR page पर API call window खोलें, token लेने के लिए click करें, फिर उसे copy करें।
ImgBed पर लौटें, PaddleOCR Token में paste करें और save करें।
Recognition शुरू करना
File Management में image या document screenshot select करें और OCR click करें।
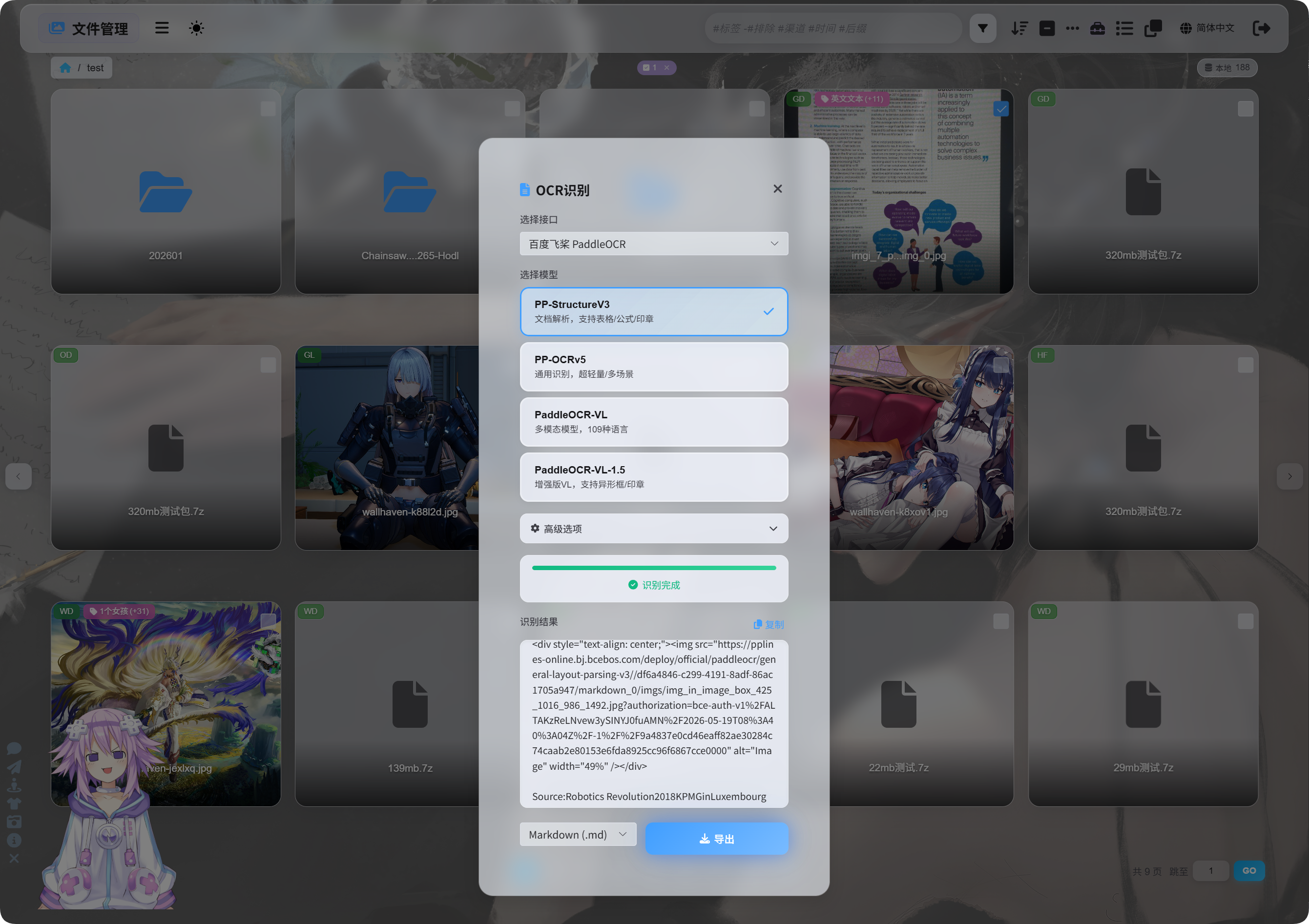
Dialog में recognition service और model चुनें।
Common PaddleOCR model choices:
| Model | Best For |
|---|---|
PP-StructureV3 | Recommended default। Documents, tables, formulas, stamps और mixed layouts के लिए अच्छा। |
PP-OCRv5 | Simple images, ordinary text और lightweight recognition। |
PaddleOCR-VL | Multilingual, complex images और chart-like content। |
PaddleOCR-VL-1.5 | ज़्यादा complex document pages और layout recovery। |
अगर unsure हैं, तो PP-StructureV3 से शुरू करें।
Advanced Options
| Option | Description |
|---|---|
| Orientation correction | Image rotated या skewed हो तो इस्तेमाल करें। |
| Document flattening | Curvature या tilt वाले photographed documents के लिए इस्तेमाल करें। |
| Layout detection | Headings, paragraphs, tables और image structure preserve करना हो तो इस्तेमाल करें। |
| Chart recognition | Image में charts या complex structures हों तो इस्तेमाल करें। |
Beautify Markdown | Exported Markdown को पढ़ने में आसान बनाता है। |
Regular screenshots के लिए options minimal रखें। Document scans के लिए document-related options ज़्यादा enable करें।
Results देखना
Recognition finish होने के बाद dialog result दिखाता है।
आप इसे directly copy कर सकते हैं या export formats चुन सकते हैं।

Document pages के लिए exported PDF page appearance preserve कर सकता है और text searchable रखता है। यह scans archive करने और बाद में content खोजने में उपयोगी है।
Export Format चुनना
| Format | Best For |
|---|---|
Markdown (.md) | Notes, documentation systems और बाद की editing। |
PDF (.pdf) | Page appearance और scanned document results preserve करना। |
Word (.docx) | Layout editing, text modification और दूसरों को handoff। |
| Export all | Multiple formats और original image save करता है, important archives के लिए suitable। |
अगर सिर्फ text चाहिए, तो Markdown export करें।
अगर page appearance चाहिए, तो PDF या Word इस्तेमाल करें।
Word Output
Exported Word documents office software में खोले और edit किए जा सकते हैं।
कुछ documents में Word output के अंदर recognized images, headings और paragraphs शामिल होते हैं।
Recognition quality original image clarity, model choice और document complexity पर depend करती है।
OCR के लिए Best File Types
| File Type | Recommendation |
|---|---|
| Clear screenshots | Direct recognize करें। |
| Scans | PP-StructureV3 prefer करें। |
| Photographed documents | Orientation correction और document flattening enable करें। |
| Tables, formulas, stamps | Structured models prefer करें। |
| Simple short text images | PP-OCRv5 आम तौर पर काफी है। |
Straight text वाली clearer images बेहतर results देती हैं।
Common Cases
| Case | Meaning |
|---|---|
| Recognition fail होता है | Check करें कि service token या key save है। |
| Recognition slow है | Complex documents और large images में ज़्यादा समय लगता है। |
| Table incomplete है | Structured model try करें। |
| Text में mistakes हैं | Blur, glare और skew recognition errors बढ़ाते हैं। Clearer image try करें। |
| Word output में बहुत images हैं | Structured models कुछ recognized images preserve कर सकते हैं। यह normal है। |
Google Quota Query fail हो रही है
Check करें:
- Service account
JSONimport हुआ है। - Service account के पास
Monitoring Viewerrole है। - Project में
Cloud Vision APIenabled है।
अगर आपको सिर्फ OCR चाहिए और usage query नहीं, तो service account JSON ignore कर सकते हैं और केवल Google Vision API Key भर सकते हैं।
Quick Flow
text
System Settings खोलें
-> Other Settings खोलें
-> OCR service credentials भरें
-> Save करें
-> File Management पर लौटें
-> File select करें और OCR click करें
-> Model चुनें
-> Recognition का इंतज़ार करें
-> Results copy करें या Markdown / PDF / Word export करें