OCR
OCR ดึง text ออกจาก images, scans และ document screenshots
หลัง recognition แล้ว คุณสามารถ copy result, export เป็น Markdown, PDF หรือ Word หรือ package หลาย formats รวมกันเพื่อ download
OCR ทำอะไรได้บ้าง
| Feature | Description |
|---|---|
| Image text recognition | Extract text จาก images, screenshots และ scans |
| Document layout recognition | เหมาะกับ tables, formulas, stamps และ mixed text-image layouts |
| Multiple services | รองรับ Baidu PaddleOCR, Microsoft Azure Vision และ Google Vision |
| Copy results | Copy recognized text หลัง processing |
| Export files | Export Markdown, PDF และ Word |
| Batch packaging | หลัง recognize หลาย files สามารถ download results เป็น package |
Configure OCR Services ก่อน
เปิด:
text
System Settings -> Other Settings -> OCR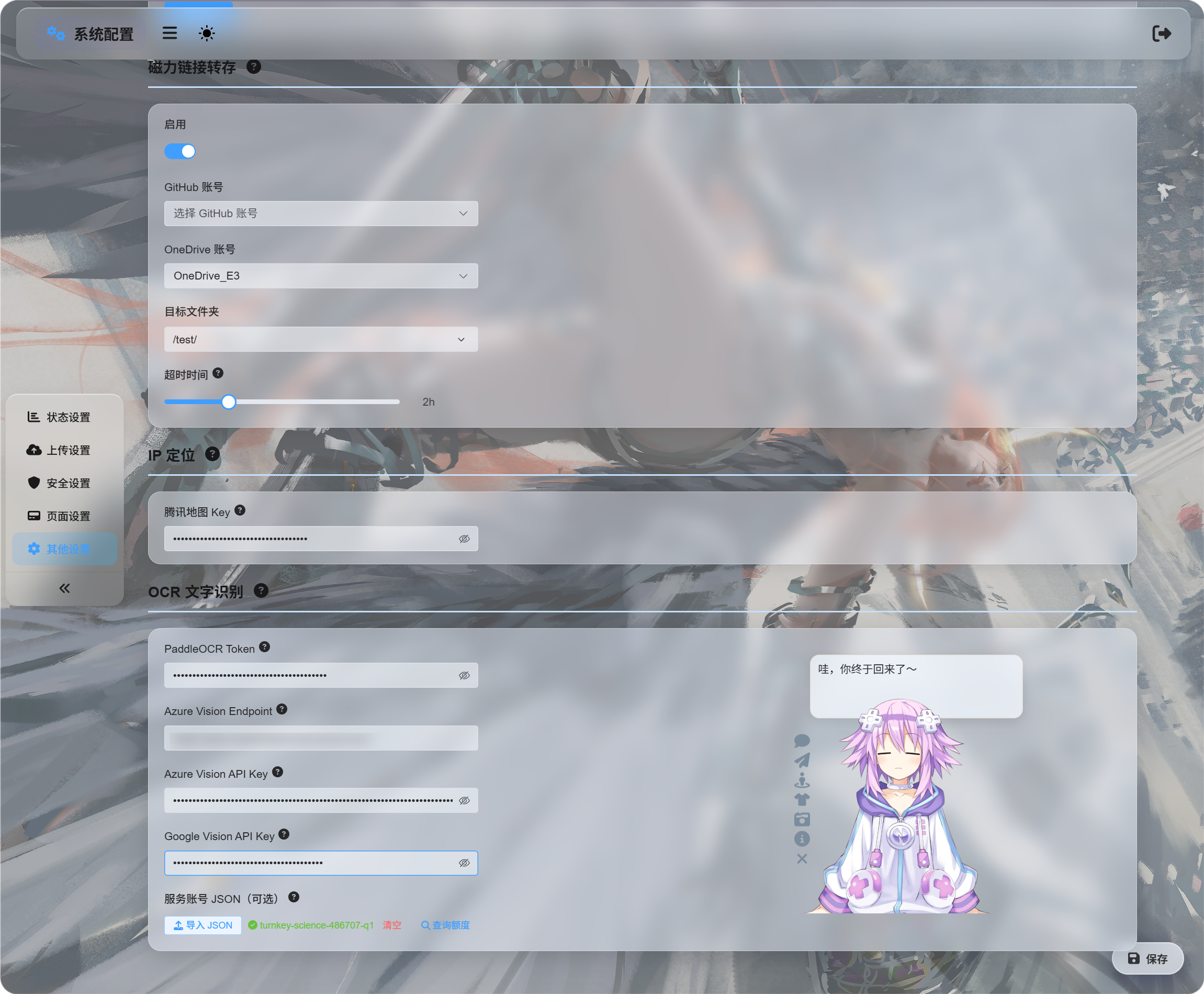
กรอก credentials สำหรับ services ที่ต้องการใช้:
| Service | What To Enter | Best For |
|---|---|---|
| Baidu PaddleOCR | PaddleOCR Token | Recommended first choice เหมาะกับ documents, images, tables และ mixed layouts |
| Microsoft Azure Vision | Azure Vision Endpoint และ Azure Vision API Key | เหมาะถ้าใช้ Microsoft cloud services อยู่แล้ว |
| Google Vision | Google Vision API Key ส่วน service account JSON ใช้เฉพาะ quota query | เหมาะถ้าใช้ Google Cloud services |
กรอก credentials แล้ว save
สำหรับ initial testing configure service เดียวก็พอ ไม่จำเป็นต้องครบทั้งสาม
Google Vision Setup
Google setup มีสองส่วน:
| Goal | Requirement |
|---|---|
| ใช้ OCR | Enable Cloud Vision API แล้วสร้าง API Key |
| Query usage | สร้าง service account, grant Monitoring Viewer, แล้ว download service account JSON |
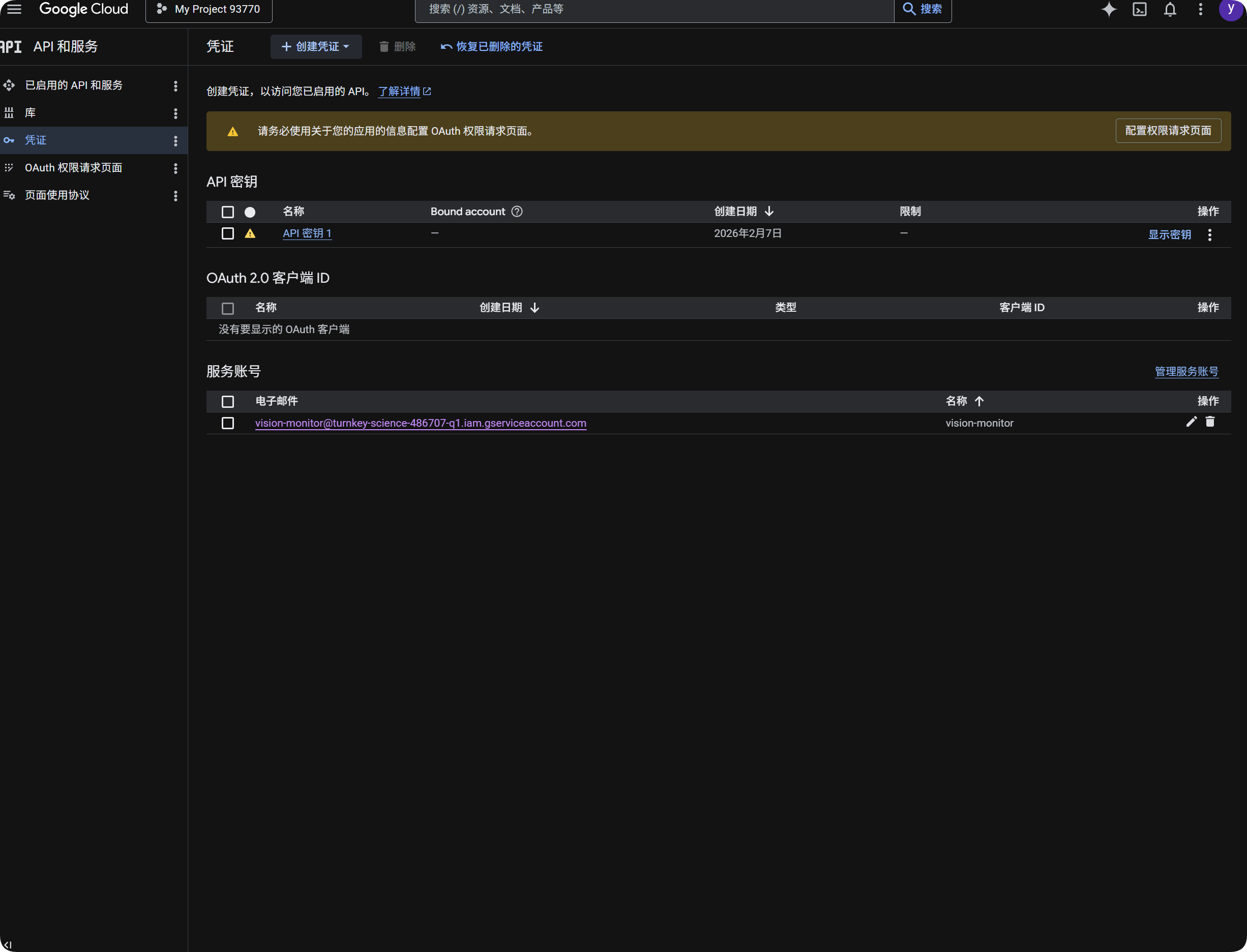
ใช้ Google สำหรับ OCR
- เปิด Google Cloud Console
- ไปที่
APIs & Services - เปิด
Library, searchCloud Vision APIแล้ว enable - กลับไปที่
Credentials - Create
API Key - เปิด API Key แล้ว copy
- Paste ใน
Google Vision API Keyของ ImgBed - Save
จากนั้นเลือก Google Vision ใน OCR dialog ได้
Query Google Usage
Quota query ไม่ required สำหรับ recognition
ใช้แสดงคร่าว ๆ ว่า Google Vision calls ถูกใช้ไปเท่าไรใน 30 วันที่ผ่านมา
- ใน Google Cloud Console เปิด
IAM & Admin - เปิด
Service Accounts - สร้าง service account เช่น
vision-monitor - Grant role
Monitoring Viewer - เปิด service account details แล้ว create key
- เลือก
JSON - Download generated JSON file
- กลับไป ImgBed แล้ว import ใน service account
JSON(optional) - หลัง import สำเร็จ คลิก quota query
หลัง import ImgBed จะแสดง project name ที่เป็นเจ้าของ service account เมื่อ query usage ImgBed จะอ่าน Google monitoring data แล้วแสดง call count ของเดือนนี้
สรุป:
| Item | Purpose |
|---|---|
Google Vision API Key | ทำ OCR recognition |
Service account JSON | Query จำนวน Google Vision calls ที่ใช้ |
Monitoring Viewer role | ให้ service account อ่าน usage data |
รับ Baidu PaddleOCR Token
Baidu PaddleOCR ต้องใช้ access token
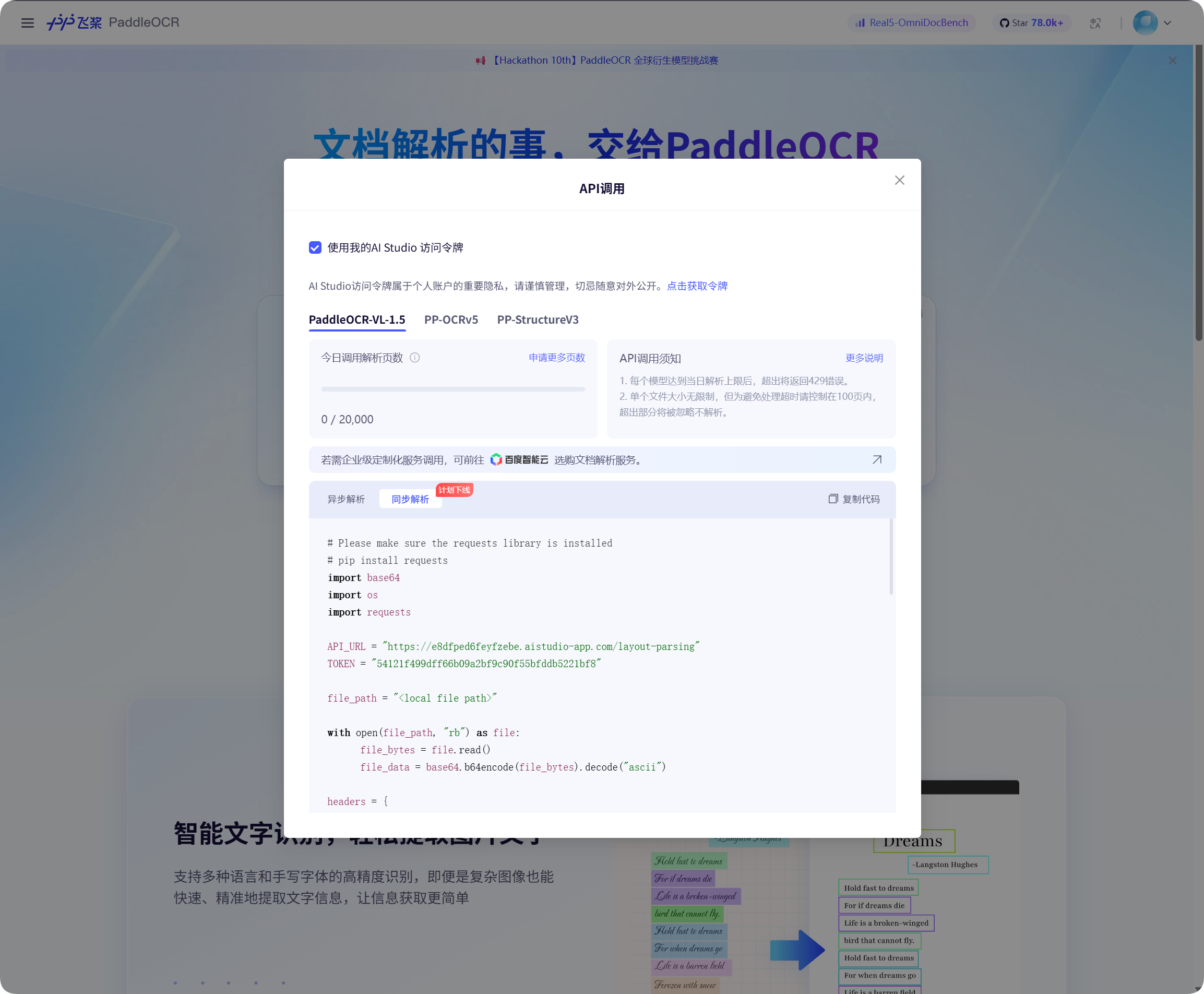
เปิด API call window ในหน้า Baidu PaddleOCR คลิกเพื่อรับ token แล้ว copy
กลับไป ImgBed paste ใน PaddleOCR Token แล้ว save
เริ่ม Recognition
ใน File Management เลือก image หรือ document screenshot แล้วคลิก OCR
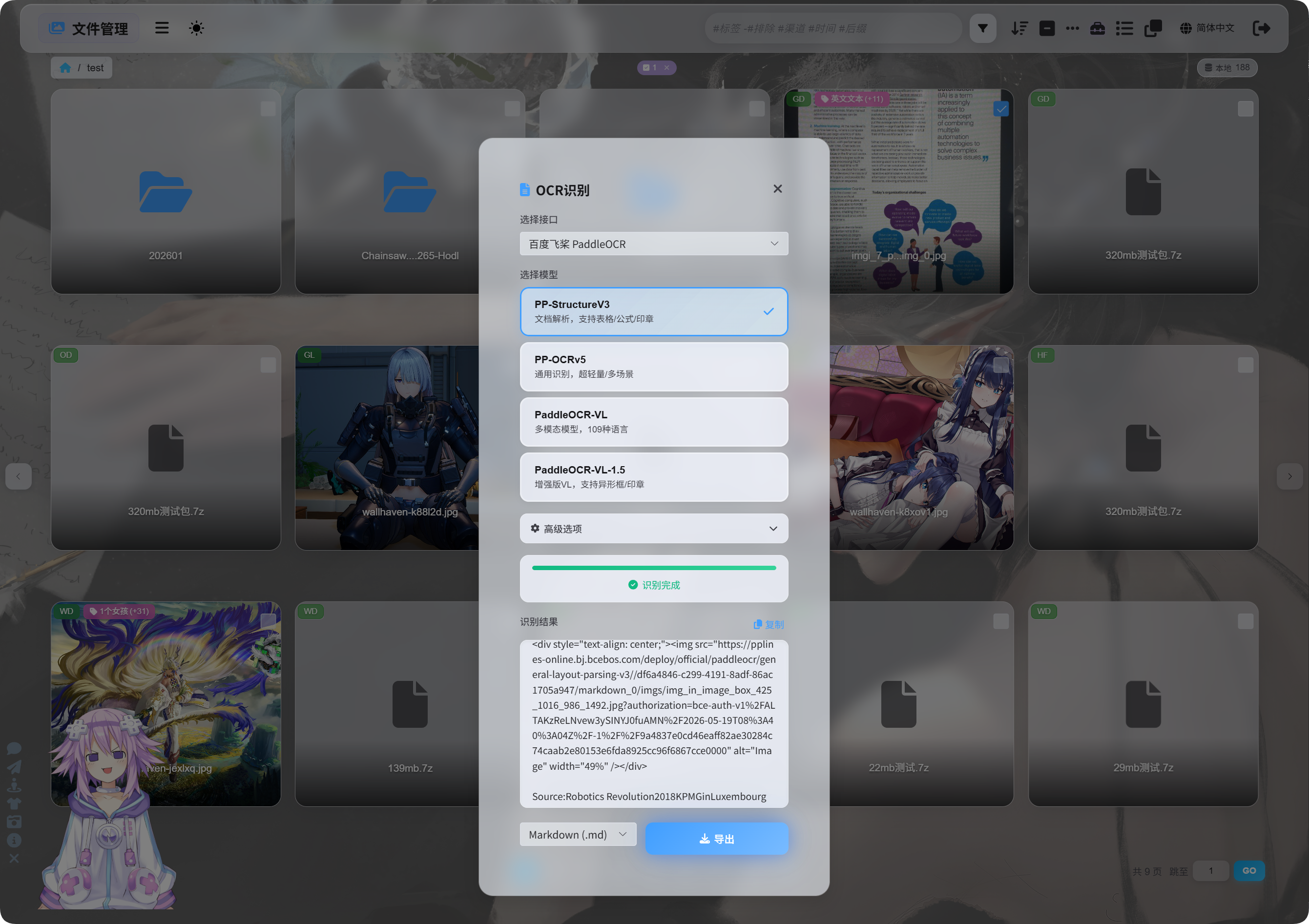
ใน dialog เลือก recognition service และ model
Common PaddleOCR model choices:
| Model | Best For |
|---|---|
PP-StructureV3 | Recommended default เหมาะกับ documents, tables, formulas, stamps และ mixed layouts |
PP-OCRv5 | Simple images, ordinary text และ lightweight recognition |
PaddleOCR-VL | Multilingual, complex images และ chart-like content |
PaddleOCR-VL-1.5 | Document pages ที่ซับซ้อนกว่า และ layout recovery |
ถ้าไม่แน่ใจ เริ่มด้วย PP-StructureV3
Advanced Options
| Option | Description |
|---|---|
| Orientation correction | ใช้เมื่อ image หมุนหรือเอียง |
| Document flattening | ใช้กับ photographed documents ที่มี curvature หรือ tilt |
| Layout detection | ใช้เมื่อต้องการ preserve headings, paragraphs, tables และ image structure |
| Chart recognition | ใช้เมื่อ image มี charts หรือ structures ซับซ้อน |
Beautify Markdown | ทำให้ exported Markdown อ่านง่ายขึ้น |
สำหรับ regular screenshots ให้ใช้ options น้อยที่สุด สำหรับ document scans ให้ enable document-related options มากขึ้น
ดู Results
หลัง recognition เสร็จ dialog จะแสดง result
คุณ copy ได้ทันทีหรือเลือก export formats

สำหรับ document pages, exported PDF สามารถ preserve page appearance พร้อมให้ text searchable เหมาะกับ archiving scans และค้นหา content ภายหลัง
เลือก Export Format
| Format | Best For |
|---|---|
Markdown (.md) | Notes, documentation systems และการ edit ภายหลัง |
PDF (.pdf) | Preserve page appearance และ scanned document results |
Word (.docx) | Layout editing, text modification และส่งต่อให้คนอื่น |
| Export all | Save multiple formats และ original image เหมาะกับ archives สำคัญ |
ถ้าต้องการแค่ text ให้ export Markdown
ถ้าต้องการ page appearance ให้ใช้ PDF หรือ Word
Word Output
Exported Word documents เปิดและ edit ด้วย office software ได้
Documents บางแบบมี recognized images, headings และ paragraphs ใน Word output
Recognition quality ขึ้นกับ original image clarity, model choice และ document complexity
File Types ที่เหมาะกับ OCR
| File Type | Recommendation |
|---|---|
| Clear screenshots | Recognize ได้โดยตรง |
| Scans | Prefer PP-StructureV3 |
| Photographed documents | Enable orientation correction และ document flattening |
| Tables, formulas, stamps | Prefer structured models |
| Simple short text images | PP-OCRv5 มักพอ |
Images ที่ชัดและ text ตรงจะให้ results ดีกว่า
Common Cases
| Case | Meaning |
|---|---|
| Recognition fails | ตรวจว่า service token หรือ key ถูก save แล้ว |
| Recognition slow | Complex documents และ large images ใช้เวลานานกว่า |
| Table incomplete | ลอง structured model |
| Text มี mistakes | Blur, glare และ skew เพิ่ม recognition errors ลอง image ที่ชัดกว่า |
| Word output มี images จำนวนมาก | Structured models อาจ preserve recognized images บางส่วน เป็นเรื่องปกติ |
Google Quota Query Fails
ตรวจว่า:
- Import service account
JSONแล้ว - Service account มี role
Monitoring Viewer - Project enable
Cloud Vision API
ถ้าต้องการแค่ OCR ไม่ต้อง query usage สามารถไม่ใส่ service account JSON และกรอกแค่ Google Vision API Key
Quick Flow
text
เปิด System Settings
-> เปิด Other Settings
-> กรอก OCR service credentials
-> Save
-> กลับไป File Management
-> เลือก file แล้วคลิก OCR
-> เลือก model
-> รอ recognition
-> Copy results หรือ export Markdown / PDF / Word