OCR
OCR haalt tekst uit afbeeldingen, scans en screenshots van documenten.
Na herkenning kun je het resultaat kopiëren, exporteren als Markdown, PDF of Word, of meerdere formaten samen downloaden als pakket.
Wat OCR kan doen
| Functie | Beschrijving |
|---|---|
| Tekstherkenning in afbeeldingen | Haalt tekst uit afbeeldingen, screenshots en scans. |
| Documentlay-outherkenning | Beter voor tabellen, formules, stempels en gemengde tekst-afbeeldinglayouts. |
| Meerdere diensten | Ondersteunt Baidu PaddleOCR, Microsoft Azure Vision en Google Vision. |
| Resultaten kopiëren | Kopieer herkende tekst na verwerking. |
| Bestanden exporteren | Exporteer Markdown, PDF en Word. |
| Batchverpakking | Download na herkenning van meerdere bestanden resultaten als pakket. |
Configureer eerst OCR-diensten
Open:
text
System Settings -> Other Settings -> OCR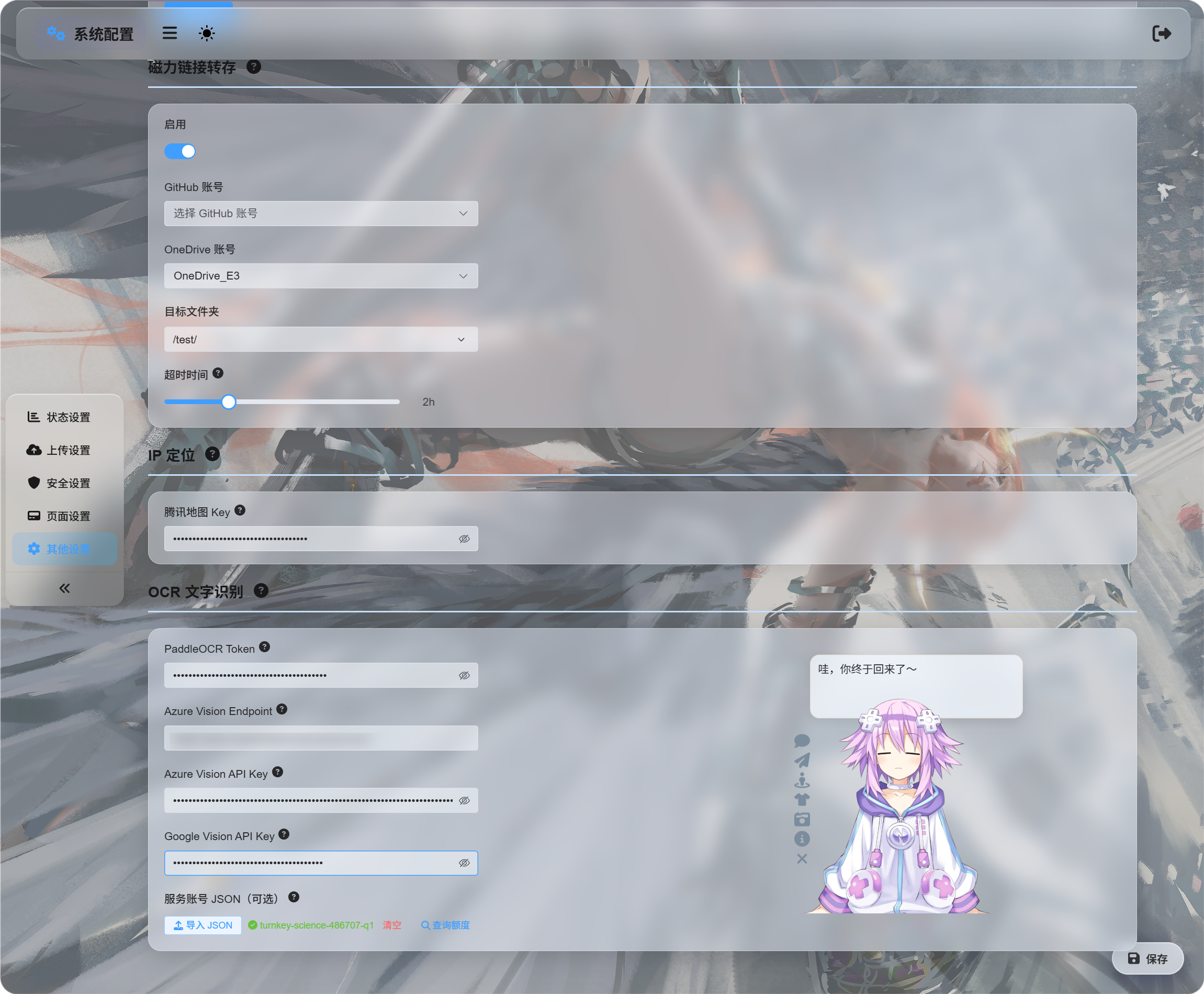
Vul gegevens in voor de diensten die je wilt gebruiken:
| Dienst | Wat je invult | Beste keuze voor |
|---|---|---|
| Baidu PaddleOCR | PaddleOCR Token | Aanbevolen eerste keuze. Goed voor documenten, afbeeldingen, tabellen en gemengde layouts. |
| Microsoft Azure Vision | Azure Vision Endpoint en Azure Vision API Key | Handig als je al Microsoft-cloudservices gebruikt. |
| Google Vision | Google Vision API Key. Serviceaccount-JSON wordt alleen gebruikt voor quota-opvraag. | Handig als je Google Cloud gebruikt. |
Sla op nadat je gegevens hebt ingevuld.
Voor een eerste test kun je één dienst configureren. Je hebt ze niet alle drie nodig.
Google Vision instellen
Google heeft twee onderdelen:
| Doel | Vereiste |
|---|---|
| OCR gebruiken | Schakel Cloud Vision API in en maak daarna een API Key. |
| Gebruik opvragen | Maak een serviceaccount, geef Monitoring Viewer en download daarna de serviceaccount-JSON. |
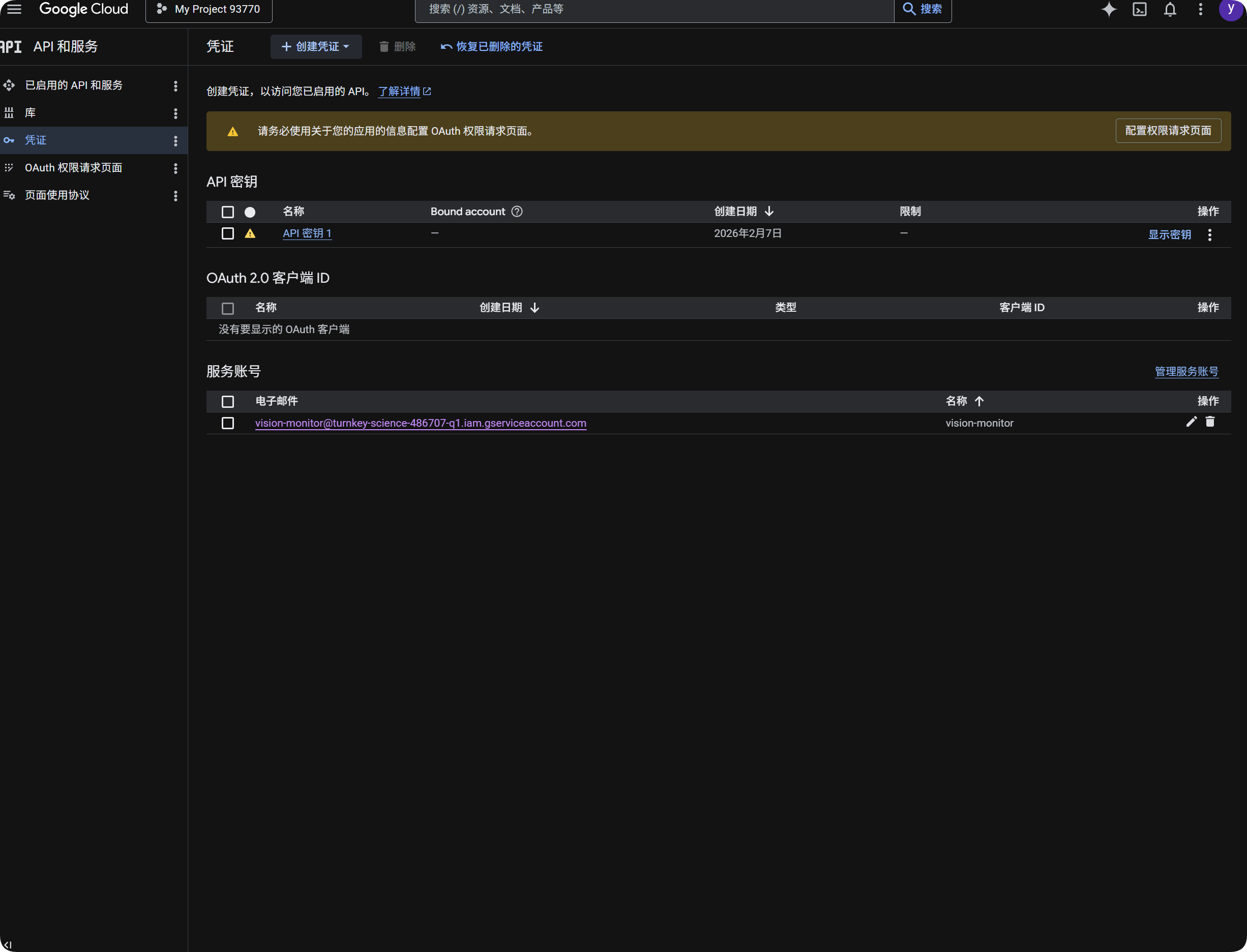
Google gebruiken voor OCR
- Open Google Cloud Console.
- Ga naar
APIs & Services. - Open
Library, zoekCloud Vision APIen schakel deze in. - Ga terug naar
Credentials. - Maak een
API Key. - Open de API Key en kopieer deze.
- Plak deze in
Google Vision API Keyin ImgBed. - Sla op.
Daarna kun je Google Vision kiezen in het OCR-venster.
Google-gebruik opvragen
Quota-opvraag is niet nodig voor herkenning.
Het toont alleen grofweg hoeveel Google Vision-aanroepen in de laatste 30 dagen zijn gebruikt.
- Open in Google Cloud Console
IAM & Admin. - Open
Service Accounts. - Maak een serviceaccount, bijvoorbeeld
vision-monitor. - Geef dit account de rol
Monitoring Viewer. - Open de details van het serviceaccount en maak een key.
- Kies
JSON. - Download het gegenereerde JSON-bestand.
- Ga terug naar ImgBed en importeer het onder serviceaccount
JSON(optioneel). - Klik na succesvolle import op quota opvragen.
Na import toont ImgBed de projectnaam van het serviceaccount. Bij het opvragen leest ImgBed Google monitoringgegevens en toont het aantal aanroepen van deze maand.
Kort gezegd:
| Item | Doel |
|---|---|
Google Vision API Key | Voert OCR-herkenning uit. |
Serviceaccount JSON | Vraagt op hoeveel Google Vision-aanroepen zijn gebruikt. |
Rol Monitoring Viewer | Laat het serviceaccount gebruiksgegevens lezen. |
Een Baidu PaddleOCR-token ophalen
Baidu PaddleOCR vereist een access token.
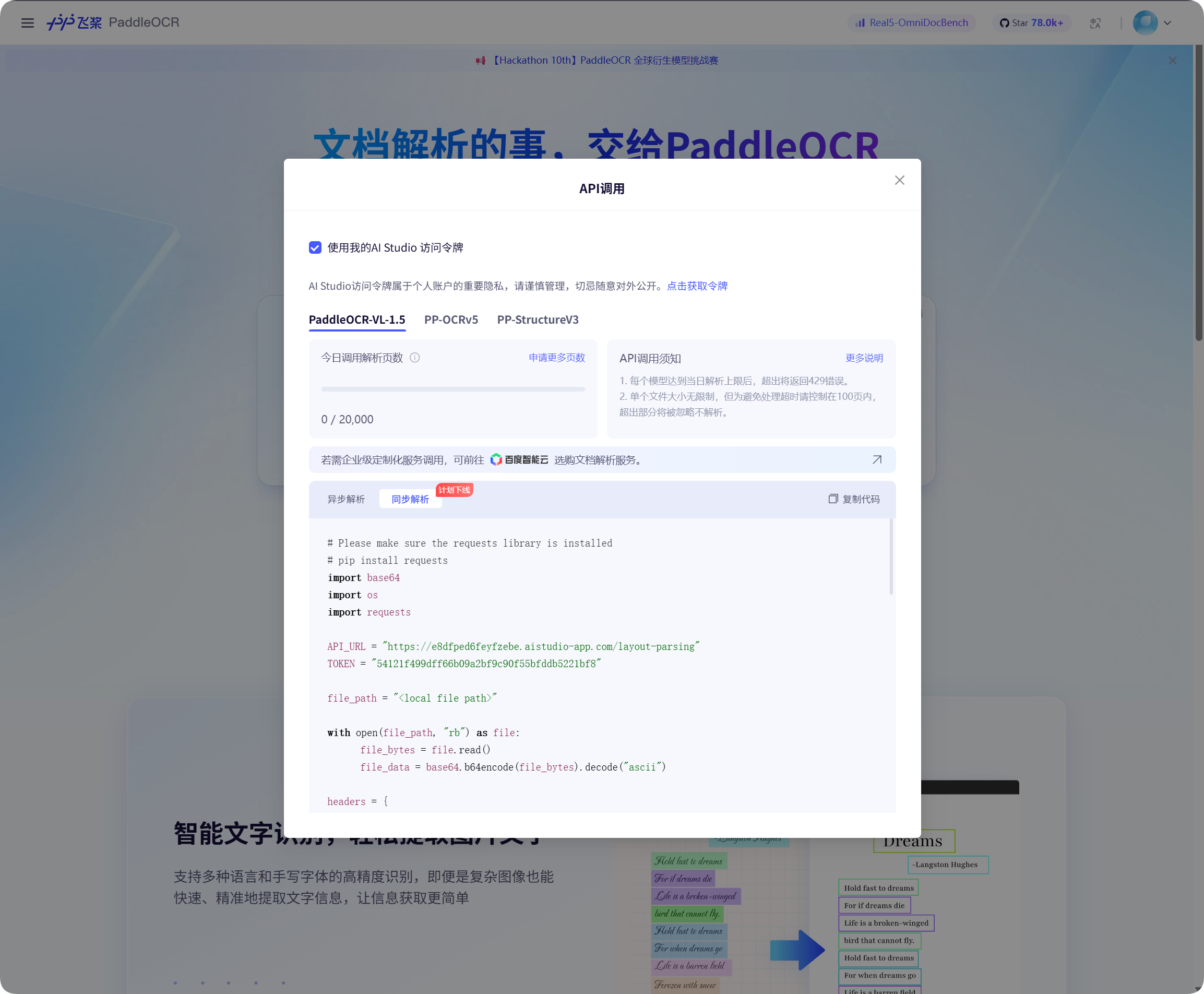
Open het API-aanroepvenster op de Baidu PaddleOCR-pagina, klik om een token te krijgen en kopieer het.
Ga terug naar ImgBed, plak het in PaddleOCR Token en sla op.
Herkenning starten
Selecteer in Bestandsbeheer een afbeelding of documentscreenshot en klik op OCR.
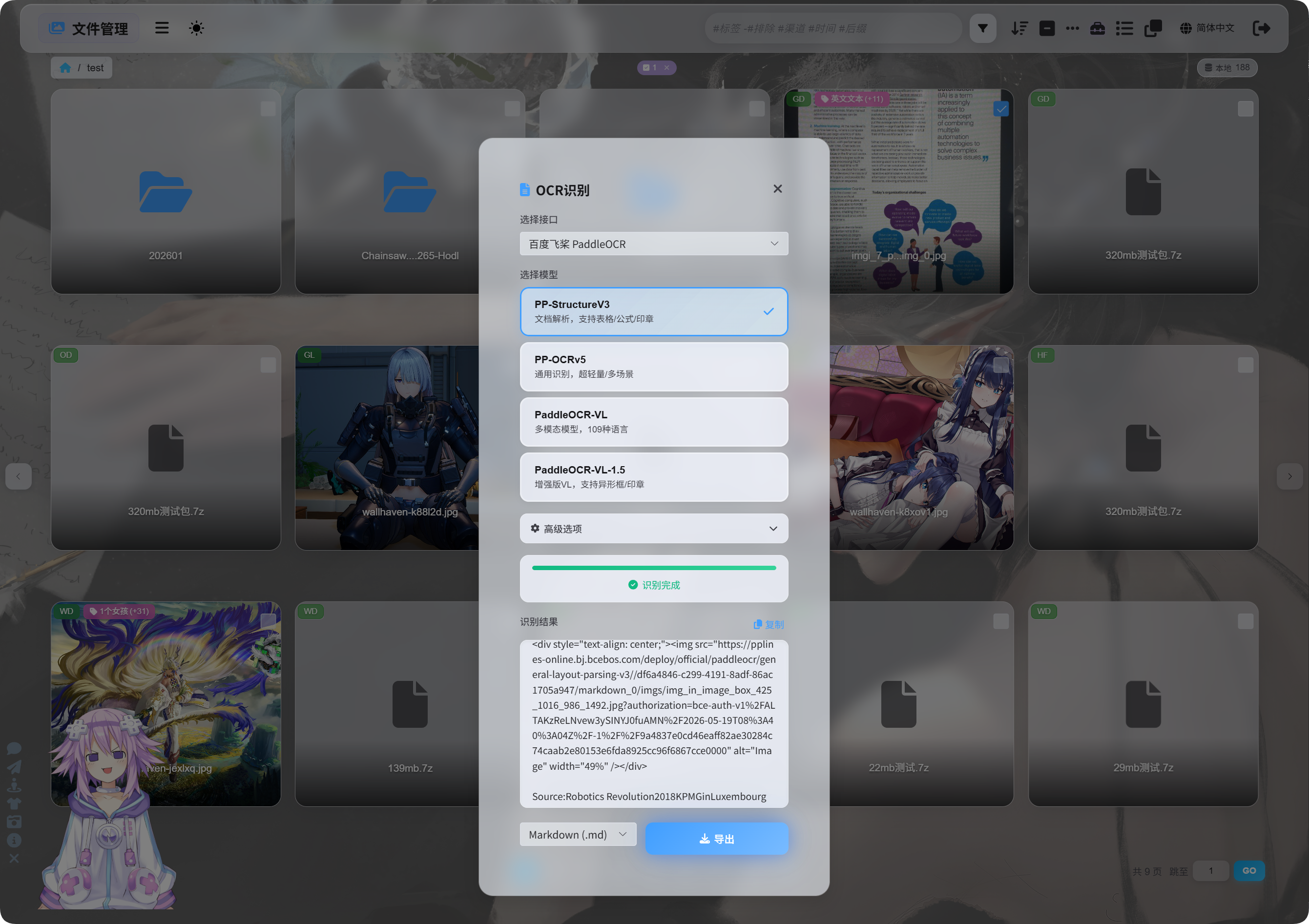
Kies in het venster de herkenningsdienst en het model.
Veelgebruikte PaddleOCR-modellen:
| Model | Beste keuze voor |
|---|---|
PP-StructureV3 | Aanbevolen standaard. Goed voor documenten, tabellen, formules, stempels en gemengde layouts. |
PP-OCRv5 | Eenvoudige afbeeldingen, gewone tekst en lichte herkenning. |
PaddleOCR-VL | Meertalig, complexe afbeeldingen en inhoud met grafieken. |
PaddleOCR-VL-1.5 | Complexere documentpagina's en layoutreconstructie. |
Weet je het niet zeker, begin dan met PP-StructureV3.
Geavanceerde opties
| Optie | Beschrijving |
|---|---|
| Oriëntatiecorrectie | Gebruik wanneer de afbeelding gedraaid of scheef is. |
| Document afvlakken | Gebruik voor gefotografeerde documenten met kromming of perspectief. |
| Layoutdetectie | Gebruik wanneer je koppen, alinea's, tabellen en afbeeldingsstructuur wilt behouden. |
| Grafiekherkenning | Gebruik wanneer de afbeelding grafieken of complexe structuren bevat. |
Markdown verbeteren | Maakt geëxporteerde Markdown leesbaarder. |
Voor gewone screenshots houd je de opties beperkt. Voor documentscans schakel je meer documentgerichte opties in.
Resultaten bekijken
Wanneer herkenning klaar is, toont het venster het resultaat.
Je kunt het direct kopiëren of exportformaten kiezen.

Voor documentpagina's kan geëxporteerde PDF de paginaweergave behouden en tegelijk tekst doorzoekbaar maken. Dat is handig voor archiveren van scans en later terugvinden van inhoud.
Exportformaat kiezen
| Formaat | Beste keuze voor |
|---|---|
Markdown (.md) | Notities, documentatiesystemen en later bewerken. |
PDF (.pdf) | Paginaweergave bewaren en scanresultaten archiveren. |
Word (.docx) | Layout verder bewerken, tekst aanpassen en delen met anderen. |
| Alles exporteren | Slaat meerdere formaten en de oorspronkelijke afbeelding op, geschikt voor belangrijke archieven. |
Heb je alleen tekst nodig, exporteer dan Markdown.
Heb je paginaweergave nodig, gebruik dan PDF of Word.
Word-uitvoer
Geëxporteerde Word-documenten kunnen met office-software worden geopend en bewerkt.
Sommige documenten bevatten herkende afbeeldingen, koppen en alinea's in de Word-uitvoer.
De kwaliteit hangt af van de scherpte van het origineel, de modelkeuze en de complexiteit van het document.
Beste bestandstypen voor OCR
| Bestandstype | Aanbeveling |
|---|---|
| Duidelijke screenshots | Direct herkennen. |
| Scans | Kies bij voorkeur PP-StructureV3. |
| Gefotografeerde documenten | Schakel oriëntatiecorrectie en documentafvlakking in. |
| Tabellen, formules, stempels | Gebruik bij voorkeur gestructureerde modellen. |
| Eenvoudige korte tekstafbeeldingen | PP-OCRv5 is meestal voldoende. |
Duidelijkere afbeeldingen met rechtere tekst leveren meestal betere resultaten op.
Veelvoorkomende situaties
| Situatie | Betekenis |
|---|---|
| Herkenning mislukt | Controleer of het servicetoken of de key is opgeslagen. |
| Herkenning is traag | Complexe documenten en grote afbeeldingen kosten meer tijd. |
| Tabel is onvolledig | Probeer een gestructureerd model. |
| Tekst bevat fouten | Onscherpte, reflectie en scheefstand vergroten herkenningsfouten. Probeer een duidelijkere afbeelding. |
| Word-uitvoer bevat veel afbeeldingen | Gestructureerde modellen kunnen sommige herkende afbeeldingen behouden. Dat is normaal. |
Google quota-opvraag mislukt
Controleer:
- Serviceaccount-
JSONis geïmporteerd. - Het serviceaccount heeft de rol
Monitoring Viewer. Cloud Vision APIis ingeschakeld voor het project.
Heb je alleen OCR nodig en geen gebruiksopvraag, dan kun je de serviceaccount-JSON negeren en alleen Google Vision API Key invullen.
Snelle flow
text
Open System Settings
-> Open Other Settings
-> Vul OCR-servicegegevens in
-> Sla op
-> Ga terug naar Bestandsbeheer
-> Selecteer een bestand en klik OCR
-> Kies een model
-> Wacht op herkenning
-> Kopieer resultaten of exporteer Markdown / PDF / Word