OCR 文字辨識使用說明
OCR 文字辨識可以把圖片、掃描件、文件截圖中的文字辨識出來。
辨識完成後,可以直接複製結果,也可以匯出成 Markdown、PDF、Word,或把多種格式一起打包下載。
這個功能能做什麼
| 功能 | 說明 |
|---|---|
| 圖片文字辨識 | 辨識圖片、截圖、掃描件裡的文字 |
| 文件版面辨識 | 對表格、公式、印章、圖文混排比較友善 |
| 多服務選擇 | 支援百度 PaddleOCR、Microsoft Azure Vision、Google Vision |
| 結果複製 | 辨識完成後可直接複製文字結果 |
| 匯出檔案 | 支援匯出 Markdown、PDF、Word |
| 批次打包 | 多個檔案辨識後,可把結果打包下載 |
先設定辨識服務
入口在:
text
系統設定 -> 其他設定 -> OCR 文字辨識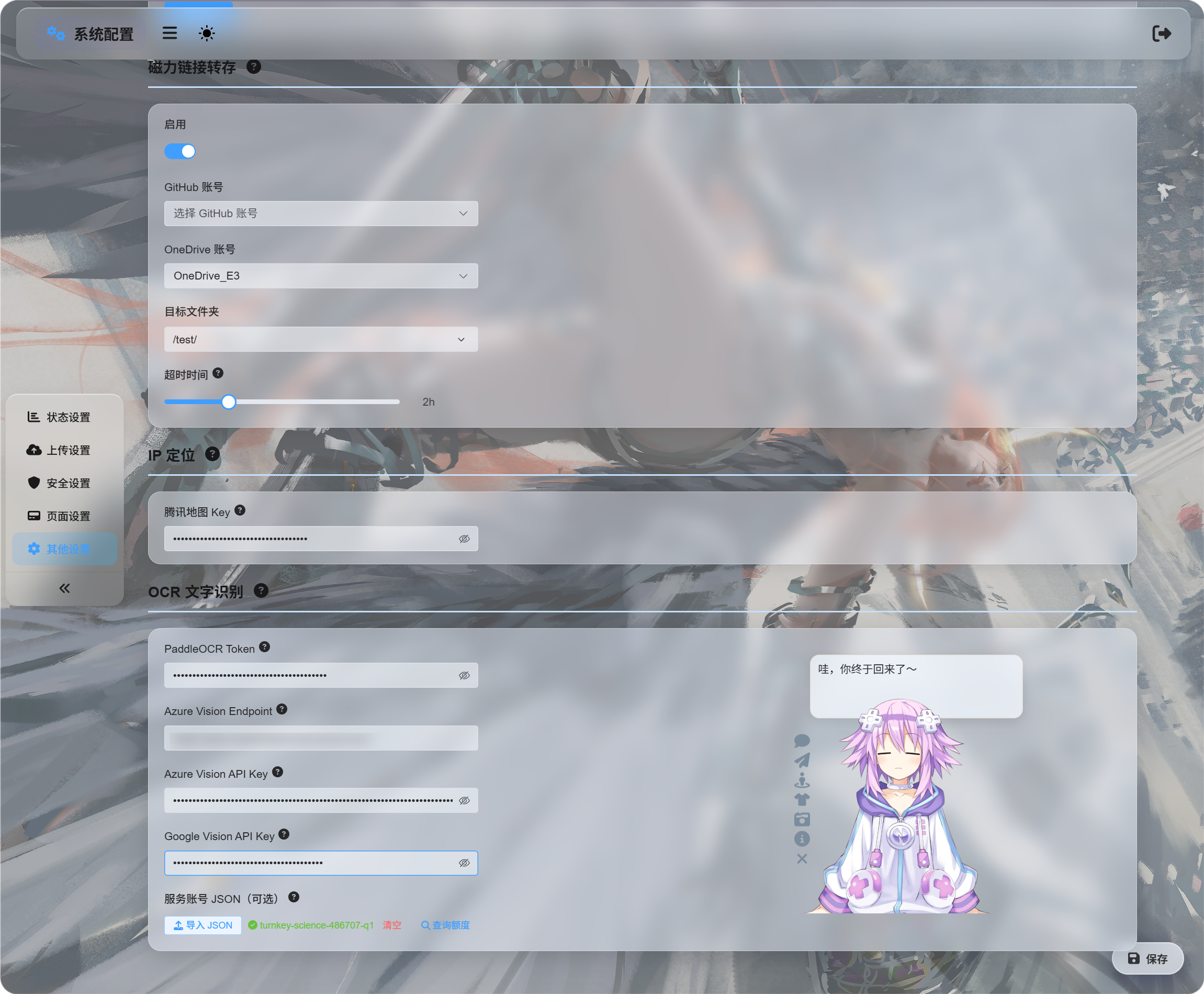
這裡可以填不同服務的憑證:
| 服務 | 後台要填什麼 | 適合情境 |
|---|---|---|
| 百度 PaddleOCR | PaddleOCR Token | 推薦優先使用,適合文件、圖片、表格、圖文混排 |
| Microsoft Azure Vision | Azure Vision Endpoint 和 Azure Vision API Key | 適合已使用 Microsoft 雲端服務的使用者 |
| Google Vision | Google Vision API Key;服務帳號 JSON 只用於查詢用量 | 適合使用 Google Cloud 的使用者 |
填好後按儲存。
如果只是先試用,可以先設定一個服務,不需要三個都填。
Google Vision 怎麼設定
Google 這裡分兩件事:
| 要做什麼 | 需要準備什麼 |
|---|---|
| 使用 OCR | 啟用 Cloud Vision API,再建立 API Key |
| 查詢使用次數 | 建立服務帳號,授予 Monitoring Viewer 角色,再下載服務帳號 JSON |
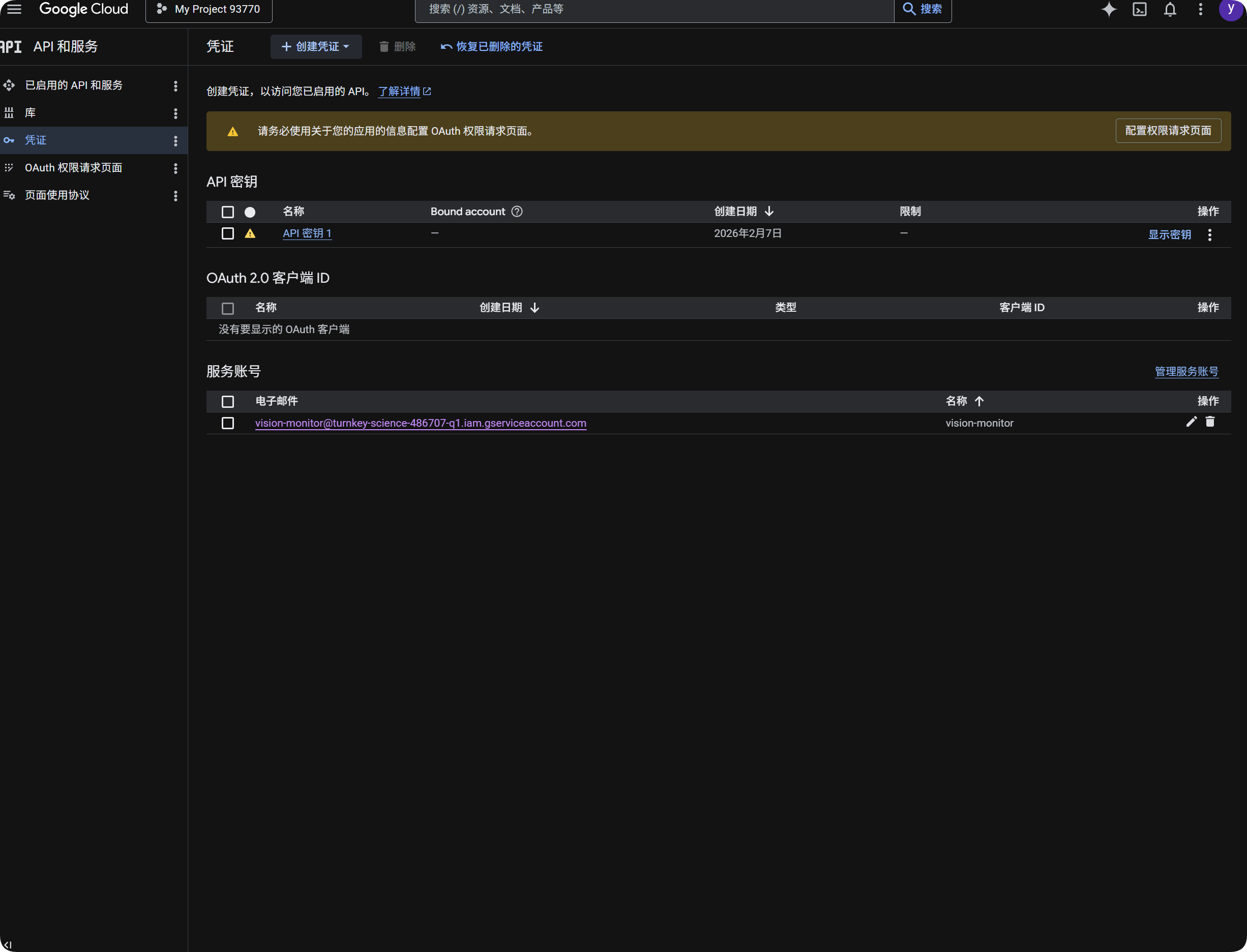
用 Google 做 OCR
- 打開 Google Cloud Console。
- 進入
API 和服務。 - 打開
程式庫,搜尋並啟用Cloud Vision API。 - 回到
憑證。 - 建立
API Key。 - 打開這組 API Key,複製金鑰內容。
- 回到 ImgBed 後台,貼到
Google Vision API Key。 - 儲存。
這樣就可以在 OCR 彈窗裡選 Google Vision 來辨識圖片。
查詢 Google 使用次數
查詢額度不是辨識必需項,只是用來查看 Google Vision 最近 30 天大約用了多少次。
- 在 Google Cloud Console 進入
IAM 和管理。 - 打開
服務帳號。 - 建立服務帳號,例如
vision-monitor。 - 給這個服務帳號
Monitoring Viewer角色。 - 進入服務帳號詳情,建立金鑰。
- 金鑰類型選
JSON。 - 下載產生的 JSON 檔。
- 回 ImgBed 後台,在服務帳號 JSON 欄位匯入。
- 匯入成功後,再點查詢額度。
簡單理解:
| 項目 | 作用 |
|---|---|
Google Vision API Key | 實際用來辨識圖片 |
服務帳號 JSON | 用來查詢 Google Vision 用了多少次 |
Monitoring Viewer 角色 | 讓服務帳號可以讀取用量資料 |
取得百度 PaddleOCR Token
百度 PaddleOCR 需要先取得存取 Token。
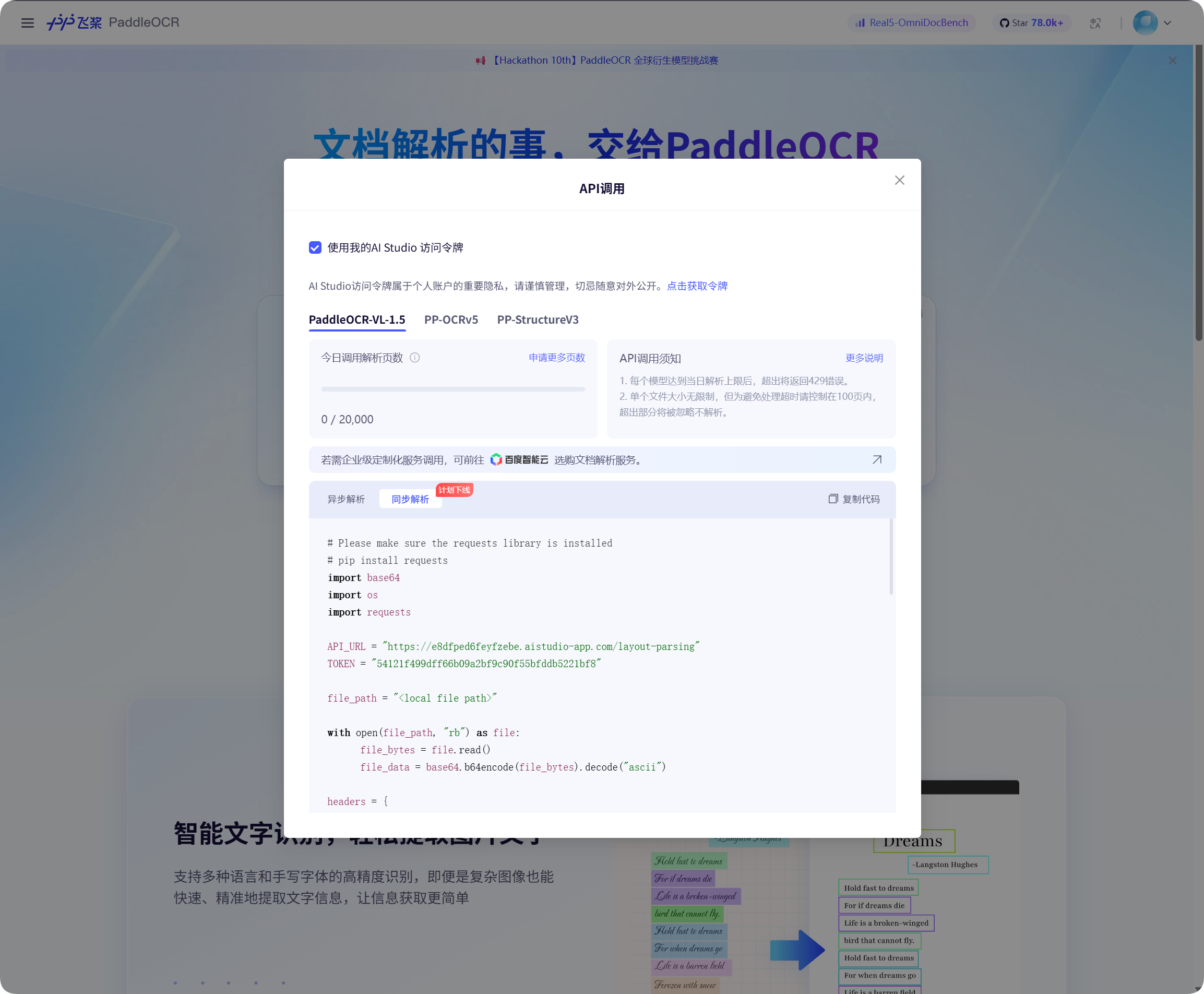
在百度 PaddleOCR 頁面打開 API 呼叫視窗,點取得 Token,然後複製 Token 內容。
回到 ImgBed 後台,把 Token 貼到 PaddleOCR Token 並儲存。
開始辨識
在檔案管理裡選中一張圖片或文件截圖,點 OCR 按鈕。
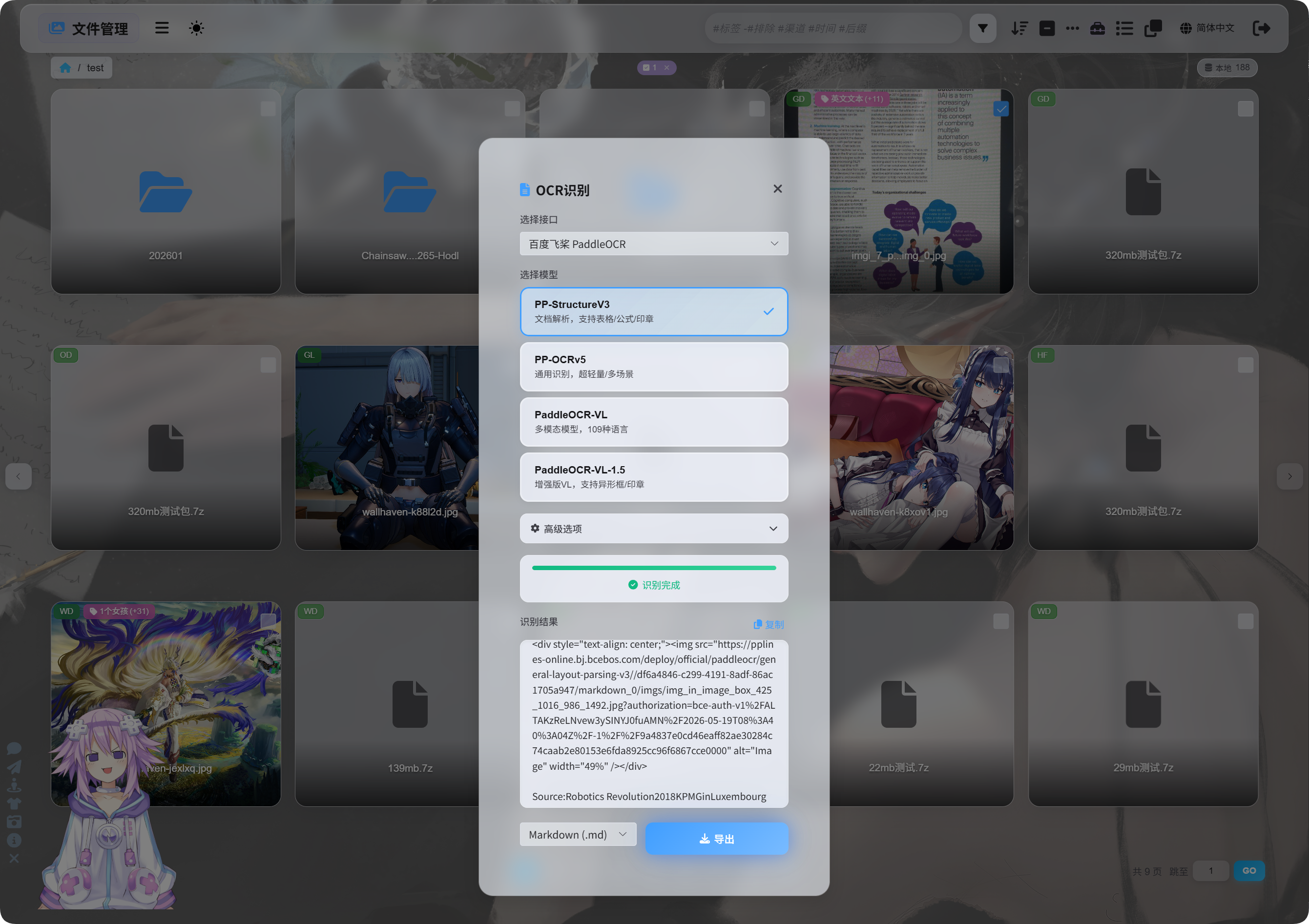
彈窗裡可以選辨識服務和模型。
百度 PaddleOCR 常用模型可這樣選:
| 模型 | 適合情境 |
|---|---|
PP-StructureV3 | 推薦預設使用,適合文件、表格、公式、印章、圖文混排 |
PP-OCRv5 | 適合簡單圖片、普通文字、輕量辨識 |
PaddleOCR-VL | 適合多語、複雜圖片、圖表類內容 |
PaddleOCR-VL-1.5 | 適合更複雜的文件頁面和版面還原 |
不確定選哪個時,先用 PP-StructureV3。
進階選項
辨識彈窗裡有進階選項,常見理解如下:
| 選項 | 說明 |
|---|---|
| 方向校正 | 圖片拍歪或旋轉時可以開 |
| 文件展平 | 拍照文件有彎曲、傾斜時可以開 |
| 版面偵測 | 想保留標題、段落、表格、圖片結構時建議開 |
| 圖表辨識 | 圖片裡有圖表或複雜結構時再開 |
| 美化 Markdown | 匯出 Markdown 時比較容易閱讀 |
一般截圖可以少開選項;掃描文件可以多開一些。
查看辨識結果
辨識完成後,彈窗會顯示結果。
可以直接複製,也可以選擇匯出格式後匯出。

如果辨識的是文件頁面,PDF 匯出後可以保留頁面效果,文字也可以搜尋。這類結果適合保存原始版面,後續查找內容也方便。
匯出格式怎麼選
| 匯出格式 | 適合情境 |
|---|---|
Markdown (.md) | 整理筆記、貼到文件系統、後續繼續編輯 |
PDF (.pdf) | 保留頁面效果,保存掃描件辨識結果 |
Word (.docx) | 繼續排版、修改文字、交給別人編輯 |
| 全部匯出 | 同時保存多種格式和原圖,適合重要檔案歸檔 |
如果只是要文字,匯出 Markdown 最輕。
如果還要頁面效果,匯出 PDF 或 Word 會更合適。
Word 效果
匯出 Word 後,可以用 Office 軟體打開繼續編輯。
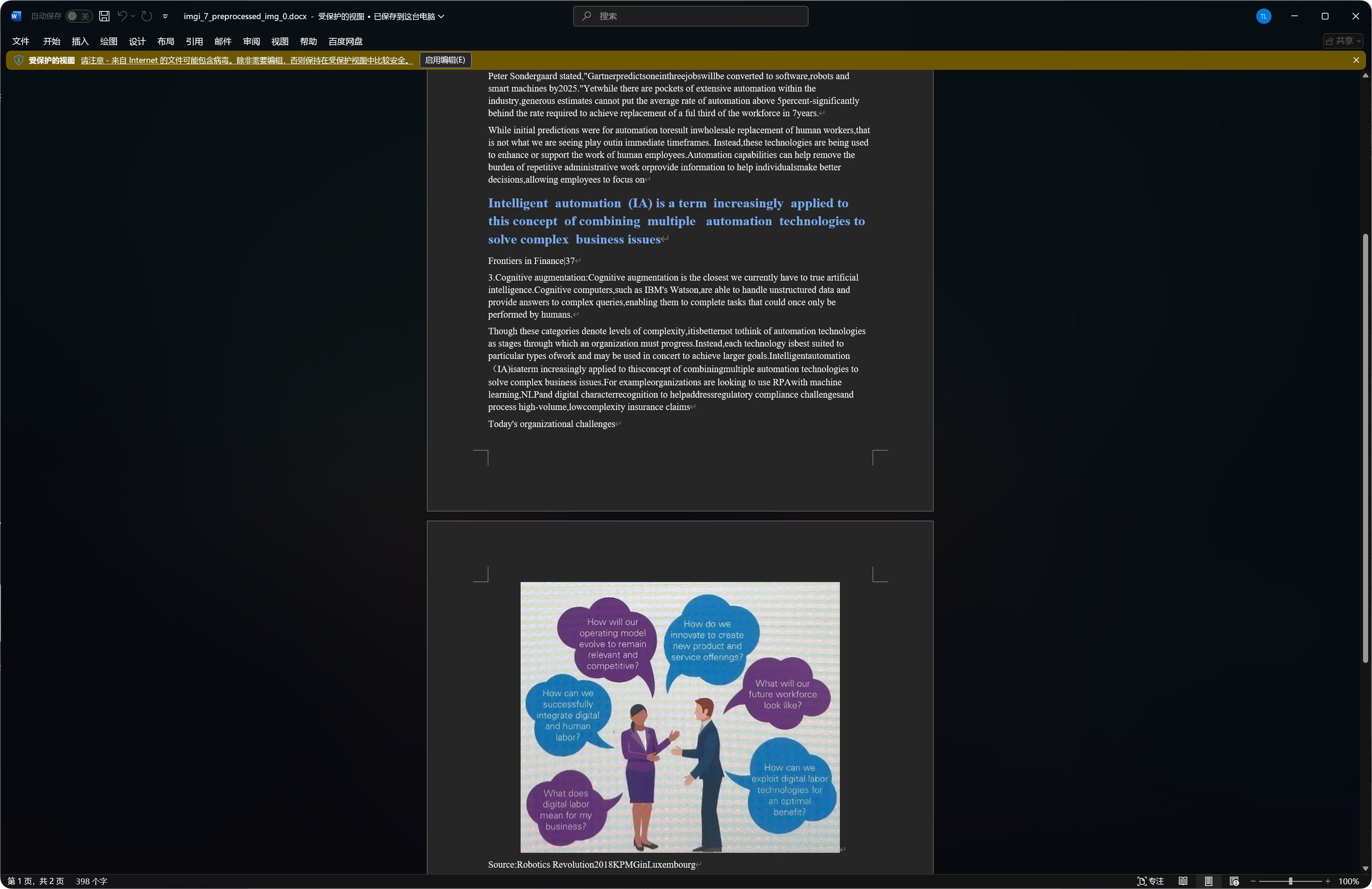
有些文件會把辨識到的圖片、標題、段落一起放進 Word。效果會受到原圖清晰度、模型選擇、文件複雜度影響。
哪些檔案更適合辨識
| 檔案類型 | 建議 |
|---|---|
| 清楚截圖 | 直接辨識即可 |
| 掃描件 | 優先用 PP-StructureV3 |
| 拍照文件 | 可以開方向校正、文件展平 |
| 表格 / 公式 / 印章 | 優先用結構化模型 |
| 普通短文字圖片 | PP-OCRv5 通常就夠用 |
圖片越清楚、文字越端正,辨識結果通常越好。
常見情況
| 情況 | 說明 |
|---|---|
| 辨識失敗 | 先檢查對應服務的 Token 或 API Key 是否已儲存 |
| 辨識很慢 | 文件越複雜、圖片越大,等待時間越長 |
| 表格不完整 | 可以換結構化模型重新辨識 |
| 文字有錯字 | 原圖模糊、反光、傾斜時更容易出錯,可換更清楚的圖片 |
| Word 裡圖片較多 | 結構化模型會保留部分辨識圖片,屬於正常情況 |
Google 查詢額度失敗
先檢查:
- 是否已匯入服務帳號 JSON。
- 服務帳號是否有
Monitoring Viewer角色。 - 目前專案是否已啟用
Cloud Vision API。
如果只是辨識圖片,不查詢次數,可以先不管服務帳號 JSON,只填 Google Vision API Key 即可。
快速流程
text
打開系統設定
-> 進入其他設定
-> 填 OCR 服務憑證
-> 儲存
-> 回到檔案管理
-> 選中檔案並點 OCR
-> 選模型
-> 等待辨識完成
-> 複製結果或匯出 Markdown / PDF / Word