OCR
OCR витягує текст із зображень, сканів і скриншотів документів.
Після розпізнавання можна скопіювати результат, експортувати його як Markdown, PDF або Word, або запакувати кілька форматів разом для завантаження.
Що може OCR
| Можливість | Опис |
|---|---|
| Розпізнавання тексту на зображенні | Витягує текст із зображень, скриншотів і сканів. |
| Розпізнавання структури документа | Краще для таблиць, формул, печаток і змішаних text-image layouts. |
| Кілька сервісів | Підтримує Baidu PaddleOCR, Microsoft Azure Vision і Google Vision. |
| Копіювання результатів | Копіює розпізнаний текст після обробки. |
| Експорт файлів | Експортує Markdown, PDF і Word. |
| Batch packaging | Після розпізнавання кількох файлів можна завантажити результати пакетом. |
Спочатку налаштуйте OCR-сервіси
Відкрийте:
text
System Settings -> Other Settings -> OCR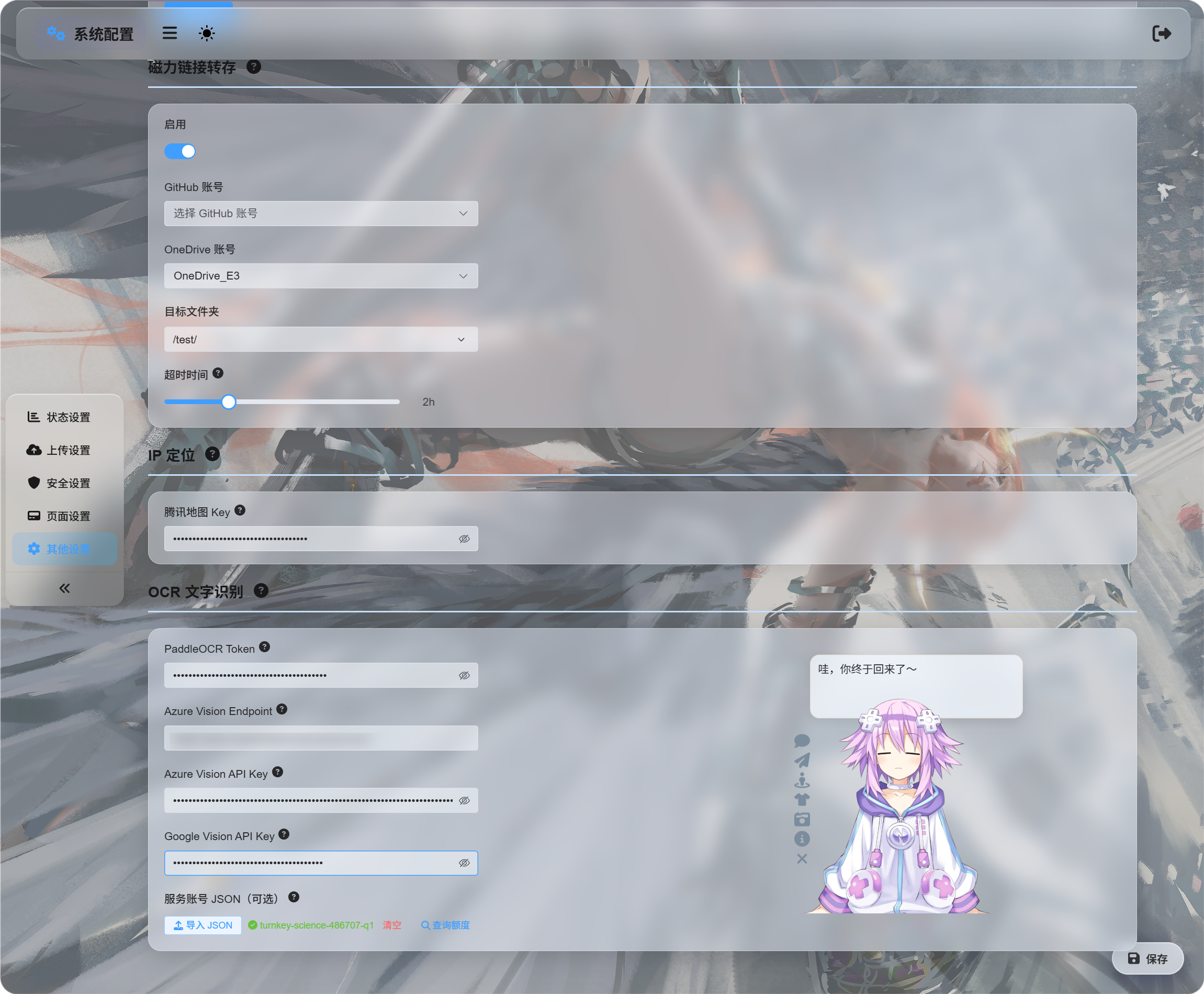
Заповніть credentials для сервісів, які хочете використовувати:
| Сервіс | Що ввести | Найкраще підходить для |
|---|---|---|
| Baidu PaddleOCR | PaddleOCR Token | Рекомендований перший вибір. Добре працює з документами, зображеннями, таблицями та змішаними layout. |
| Microsoft Azure Vision | Azure Vision Endpoint і Azure Vision API Key | Корисно, якщо ви вже користуєтеся хмарними сервісами Microsoft. |
| Google Vision | Google Vision API Key. Service account JSON використовується лише для quota query. | Корисно, якщо ви користуєтеся Google Cloud. |
Після заповнення credentials збережіть налаштування.
Для першого тесту можна налаштувати лише один сервіс. Усі три не потрібні.
Налаштування Google Vision
Налаштування Google має дві частини:
| Мета | Вимога |
|---|---|
| Використовувати OCR | Увімкнути Cloud Vision API, потім створити API Key. |
| Запитувати usage | Створити service account, надати Monitoring Viewer, потім завантажити service account JSON. |
Використання Google для OCR
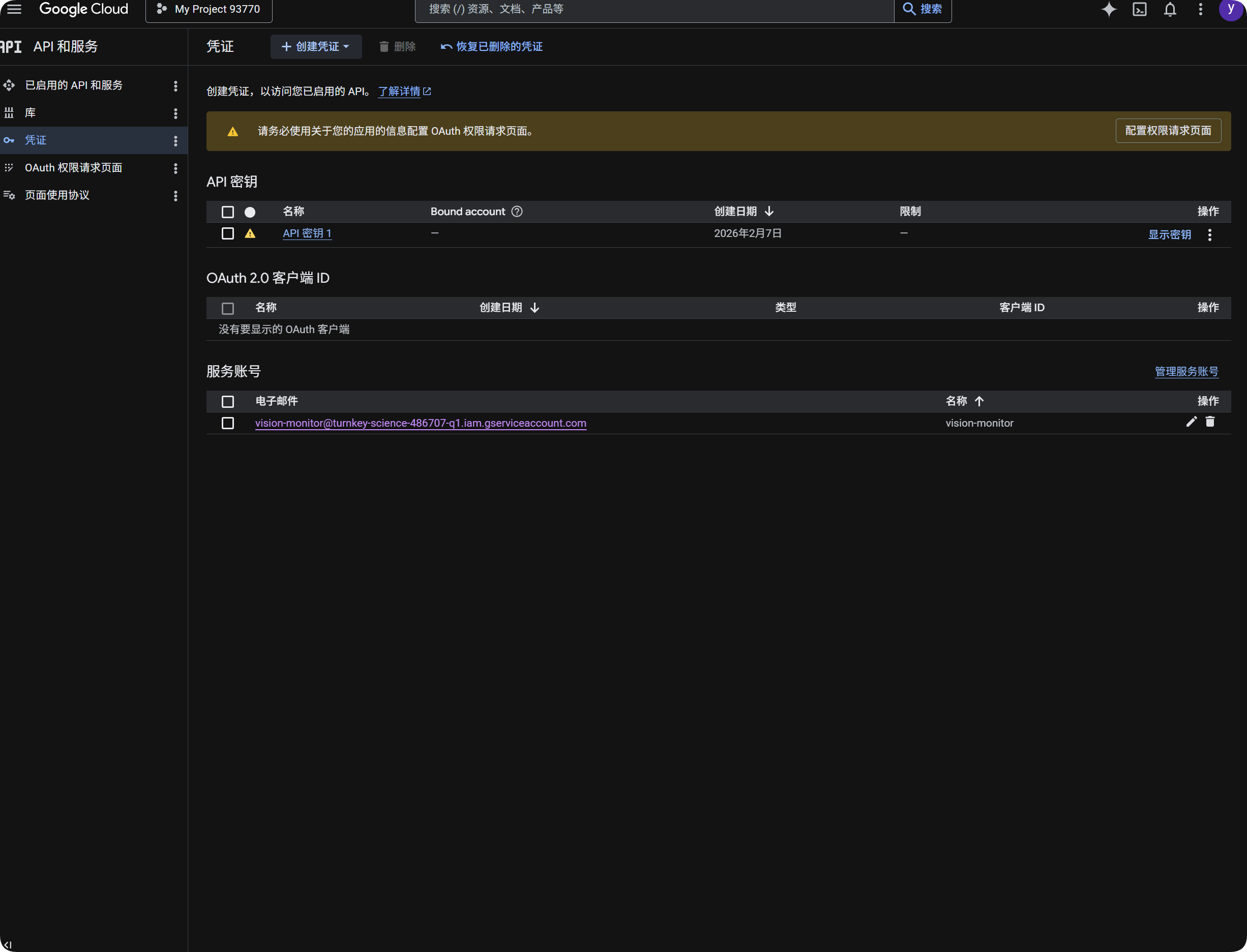
- Відкрийте Google Cloud Console.
- Перейдіть до
APIs & Services. - Відкрийте
Library, знайдітьCloud Vision APIі ввімкніть його. - Поверніться до
Credentials. - Створіть
API Key. - Відкрийте API Key і скопіюйте його.
- Вставте його в
Google Vision API Keyв ImgBed. - Збережіть.
Після цього в OCR-діалозі можна вибрати Google Vision.
Запит usage Google
Quota query не потрібен для самого розпізнавання.
Він лише приблизно показує, скільки викликів Google Vision було використано за останні 30 днів.
- У Google Cloud Console відкрийте
IAM & Admin. - Відкрийте
Service Accounts. - Створіть service account, наприклад
vision-monitor. - Надайте йому роль
Monitoring Viewer. - Відкрийте деталі service account і створіть key.
- Виберіть
JSON. - Завантажте згенерований JSON-файл.
- Поверніться до ImgBed і імпортуйте його в service account
JSON(необов'язково). - Після успішного імпорту натисніть quota query.
Після імпорту ImgBed показує project name, якому належить service account. Під час запиту usage ImgBed читає Google monitoring data і показує кількість викликів за поточний місяць.
Коротко:
| Елемент | Призначення |
|---|---|
Google Vision API Key | Виконує OCR recognition. |
Service account JSON | Запитує, скільки викликів Google Vision використано. |
Monitoring Viewer role | Дозволяє service account читати usage data. |
Отримання Baidu PaddleOCR Token
Baidu PaddleOCR потребує access token.
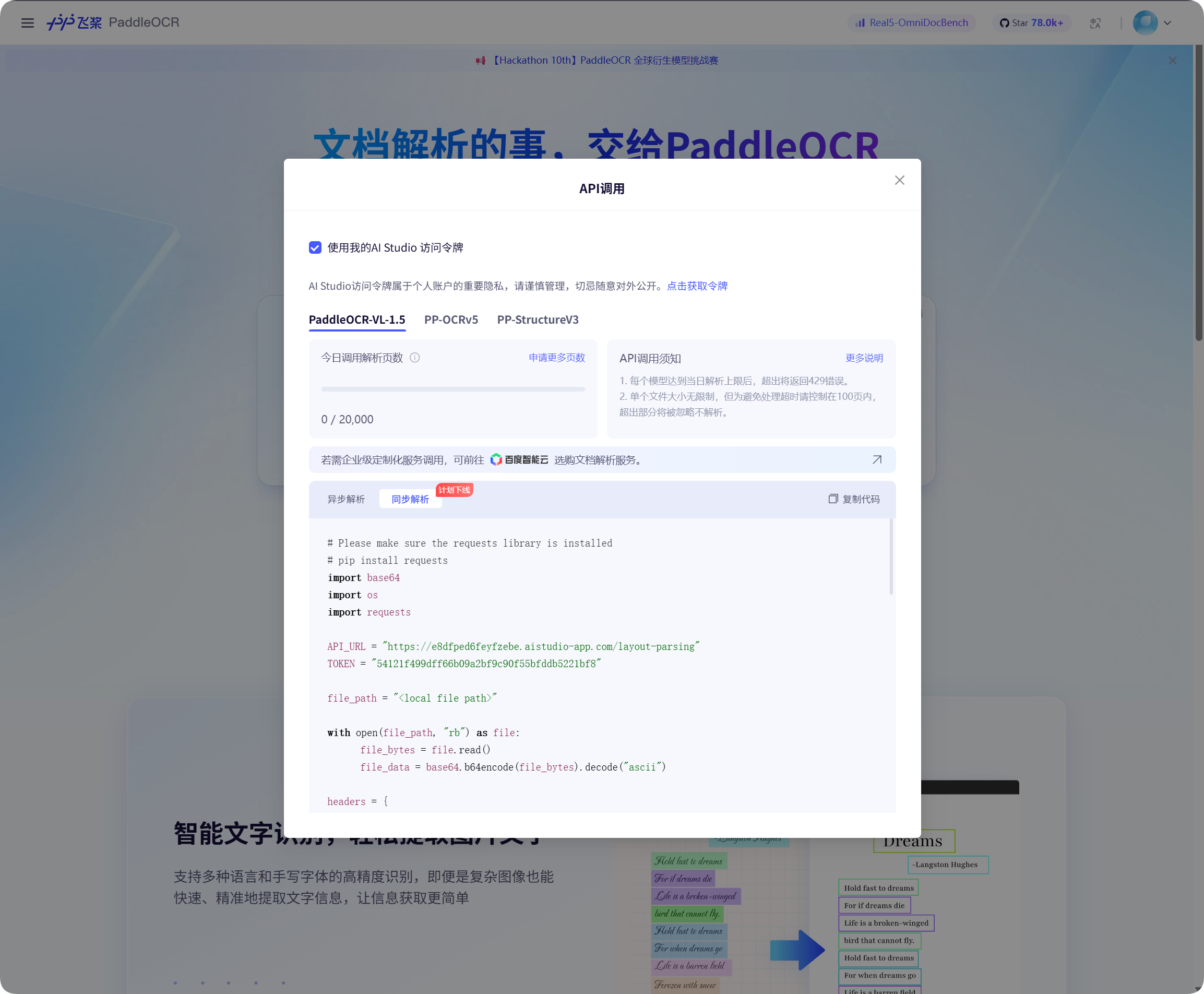
Відкрийте вікно виклику API на сторінці Baidu PaddleOCR, натисніть отримання token і скопіюйте його.
Поверніться до ImgBed, вставте його в PaddleOCR Token і збережіть.
Запуск розпізнавання
У File Management виберіть зображення або скриншот документа й натисніть OCR.
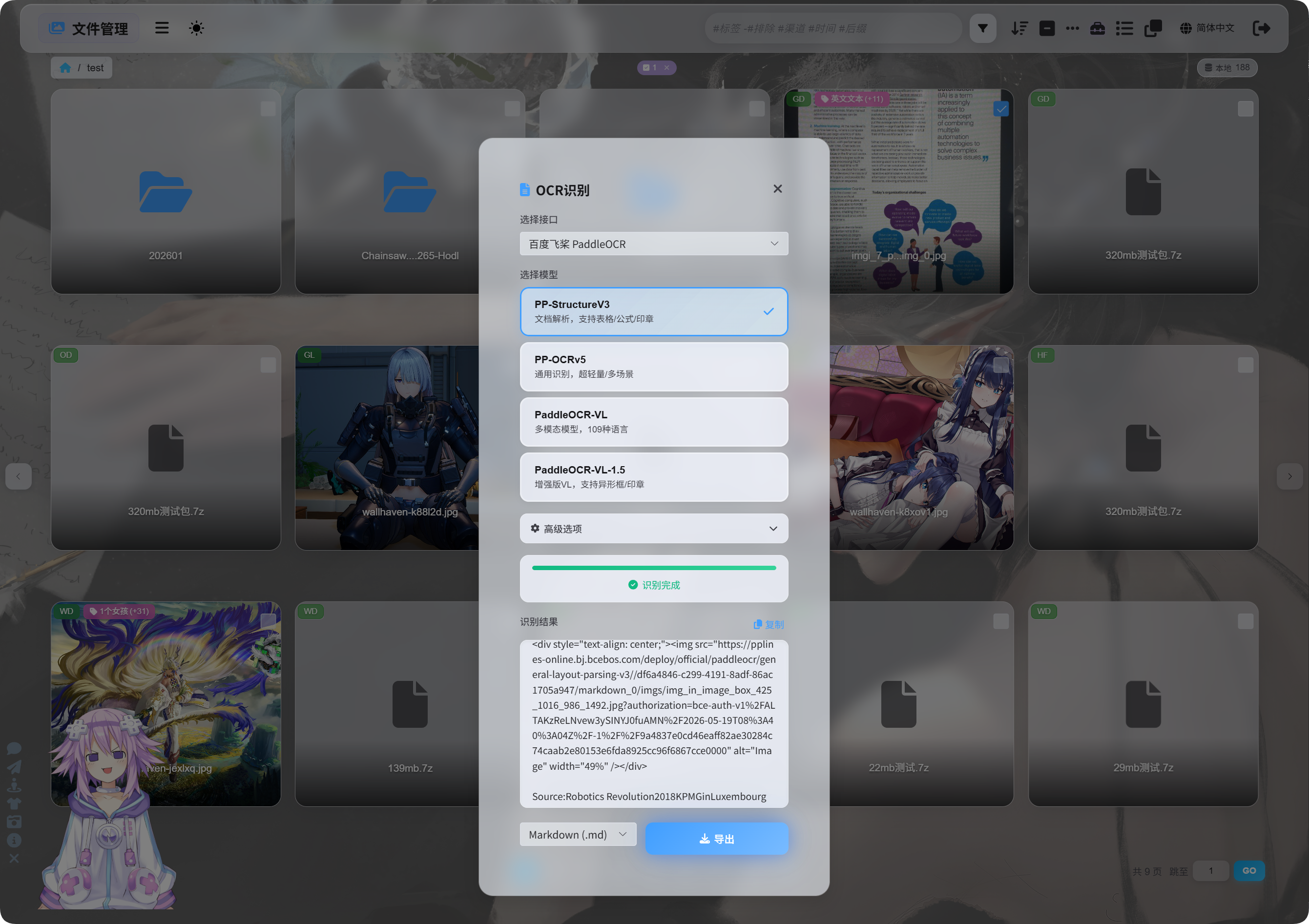
У діалозі виберіть service і model.
Поширені PaddleOCR models:
| Model | Найкраще підходить для |
|---|---|
PP-StructureV3 | Рекомендовано типово. Добре для документів, таблиць, формул, печаток і змішаних layout. |
PP-OCRv5 | Прості зображення, звичайний текст і легке розпізнавання. |
PaddleOCR-VL | Багатомовні, складні зображення та chart-like content. |
PaddleOCR-VL-1.5 | Складніші сторінки документів і відновлення layout. |
Якщо не впевнені, почніть із PP-StructureV3.
Advanced Options
| Опція | Опис |
|---|---|
| Orientation correction | Використовуйте, коли зображення повернуте або перекошене. |
| Document flattening | Для сфотографованих документів із вигином або нахилом. |
| Layout detection | Коли потрібно зберегти headings, paragraphs, tables і структуру зображень. |
| Chart recognition | Коли зображення містить charts або складні структури. |
Beautify Markdown | Робить експортований Markdown зручнішим для читання. |
Для звичайних скриншотів залишайте мінімум опцій. Для сканів документів вмикайте більше document-related options.
Перегляд результатів
Після завершення розпізнавання діалог показує результат.
Його можна скопіювати напряму або вибрати формати експорту.

Для сторінок документів експортований PDF може зберігати вигляд сторінки й водночас залишати текст придатним для пошуку. Це зручно для архівування сканів і подальшого пошуку вмісту.
Вибір формату експорту
| Формат | Найкраще для |
|---|---|
Markdown (.md) | Нотатки, документаційні системи й подальше редагування. |
PDF (.pdf) | Збереження вигляду сторінки та результатів сканованих документів. |
Word (.docx) | Подальше редагування layout, зміна тексту й передача іншим. |
| Export all | Зберігає кілька форматів і оригінальне зображення, підходить для важливих архівів. |
Якщо потрібен тільки текст, експортуйте Markdown.
Якщо важливий вигляд сторінки, використовуйте PDF або Word.
Word Output
Експортовані Word-документи можна відкривати й редагувати в office software.
Деякі документи містять розпізнані зображення, headings і paragraphs у Word output.
Якість розпізнавання залежить від чіткості оригіналу, вибору model і складності документа.
Найкращі типи файлів для OCR
| Тип файлу | Рекомендація |
|---|---|
| Чіткі скриншоти | Розпізнавати напряму. |
| Скани | Краще PP-StructureV3. |
| Сфотографовані документи | Увімкнути orientation correction і document flattening. |
| Таблиці, формули, печатки | Краще structured models. |
| Прості короткі текстові зображення | PP-OCRv5 зазвичай достатньо. |
Чіткіші зображення з рівнішим текстом зазвичай дають кращий результат.
Типові випадки
| Випадок | Значення |
|---|---|
| Recognition fails | Перевірте, чи збережено service token або key. |
| Recognition is slow | Складні документи й великі зображення потребують більше часу. |
| Table is incomplete | Спробуйте structured model. |
| Text has mistakes | Розмиття, відблиски й перекіс збільшують помилки. Спробуйте чіткіше зображення. |
| Word output contains many images | Structured models можуть зберігати частину розпізнаних зображень. Це нормально. |
Google Quota Query Fails
Перевірте:
- Service account
JSONімпортовано. - Service account має роль
Monitoring Viewer. Cloud Vision APIувімкнено для проєкту.
Якщо потрібен лише OCR, а не usage query, service account JSON можна не використовувати й заповнити тільки Google Vision API Key.
Короткий сценарій
text
Відкрити System Settings
-> Відкрити Other Settings
-> Заповнити OCR service credentials
-> Зберегти
-> Повернутися до File Management
-> Вибрати файл і натиснути OCR
-> Вибрати model
-> Дочекатися recognition
-> Скопіювати результат або експортувати Markdown / PDF / Word