OCR(文字识别)使用说明
OCR(文字识别)可以把图片、扫描件、文档截图里的文字识别出来。
识别完成后,可以复制结果,也可以导出成 Markdown(Markdown 文档)、PDF(PDF 文档)、Word(Word 文档),或者把多种格式一起打包下载。
这个功能能做什么
| 功能 | 说明 |
|---|---|
| 图片文字识别 | 识别图片、截图、扫描件里的文字。 |
| 文档版面识别 | 对表格、公式、印章、图文混排这类文档更友好。 |
| 多服务选择 | 支持百度飞桨 PaddleOCR(飞桨文字识别)、微软 Azure Vision(微软视觉识别)、谷歌 Google Vision(谷歌视觉识别)。 |
| 结果复制 | 识别完成后,可以直接复制文字结果。 |
| 导出文件 | 支持导出 Markdown(Markdown 文档)、PDF(PDF 文档)、Word(Word 文档)。 |
| 批量打包 | 多个文件识别后,可以把结果打包下载。 |
先配置识别服务
入口在:
系统配置 -> 其他设置 -> OCR(文字识别)
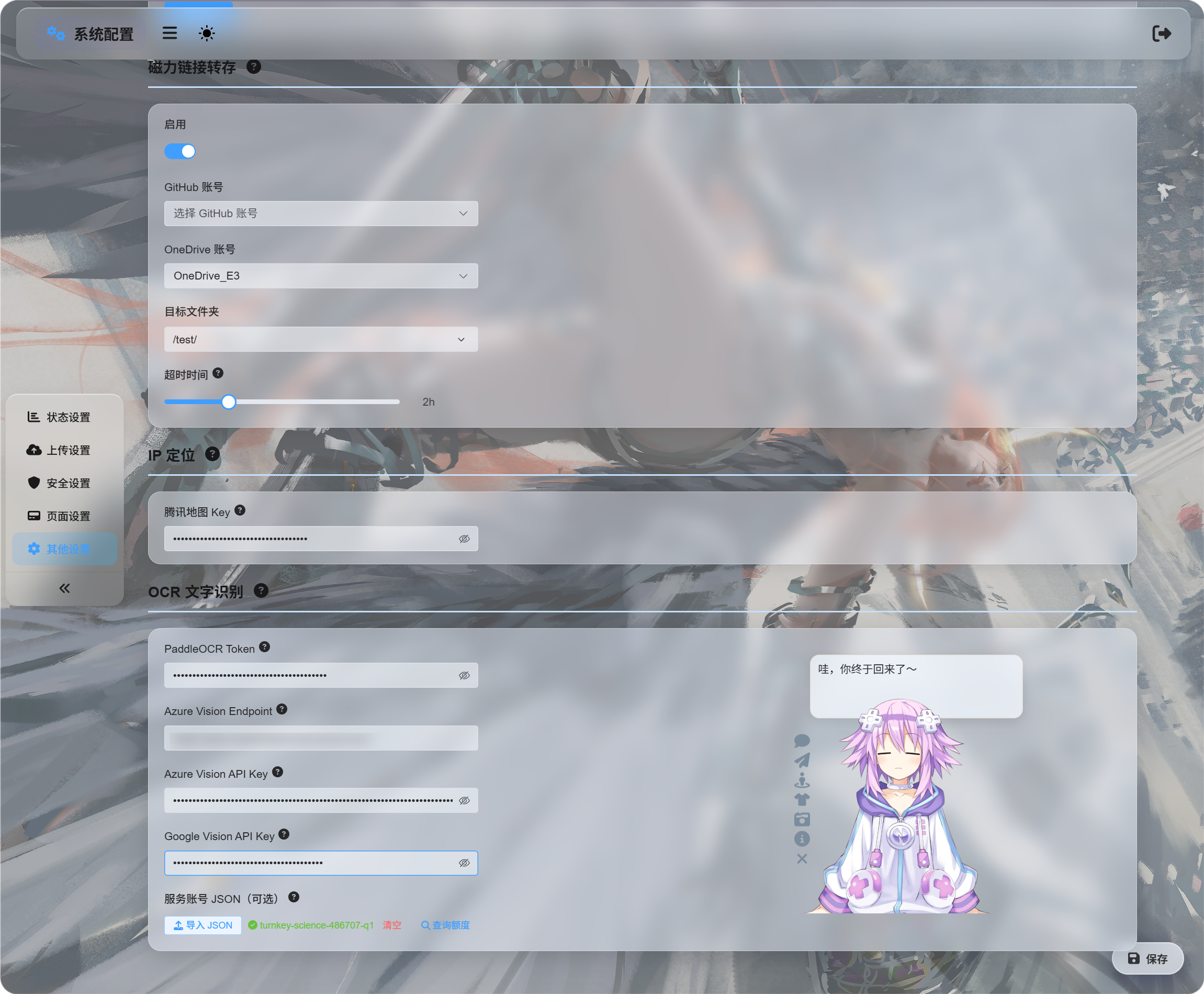
这里可以填写不同识别服务的凭据:
| 服务 | 后台要填什么 | 适合场景 |
|---|---|---|
百度飞桨 PaddleOCR(飞桨文字识别) | PaddleOCR Token(飞桨访问令牌) | 推荐优先使用,适合文档、图片、表格、图文混排。 |
微软 Azure Vision(微软视觉识别) | Azure Vision Endpoint(微软接口地址)和 Azure Vision API Key(微软密钥) | 适合使用微软云服务的用户。 |
谷歌 Google Vision(谷歌视觉识别) | Google Vision API Key(谷歌密钥)。服务账号 JSON(账号配置文件)只用于查询额度。 | 适合使用谷歌云服务的用户。 |
填好后点击保存。
只想先试用的话,可以先配置一个服务,不需要三个都填。
谷歌 Google Vision(谷歌视觉识别)怎么配置
谷歌这里分两件事:
| 要做什么 | 需要准备什么 |
|---|---|
使用 OCR(文字识别) | 启用 Cloud Vision API(云视觉接口),然后创建 API Key(接口密钥)。 |
| 查询使用次数 | 创建服务账号,给 Monitoring Viewer(监控查看者)角色,再下载服务账号 JSON(账号配置文件)。 |
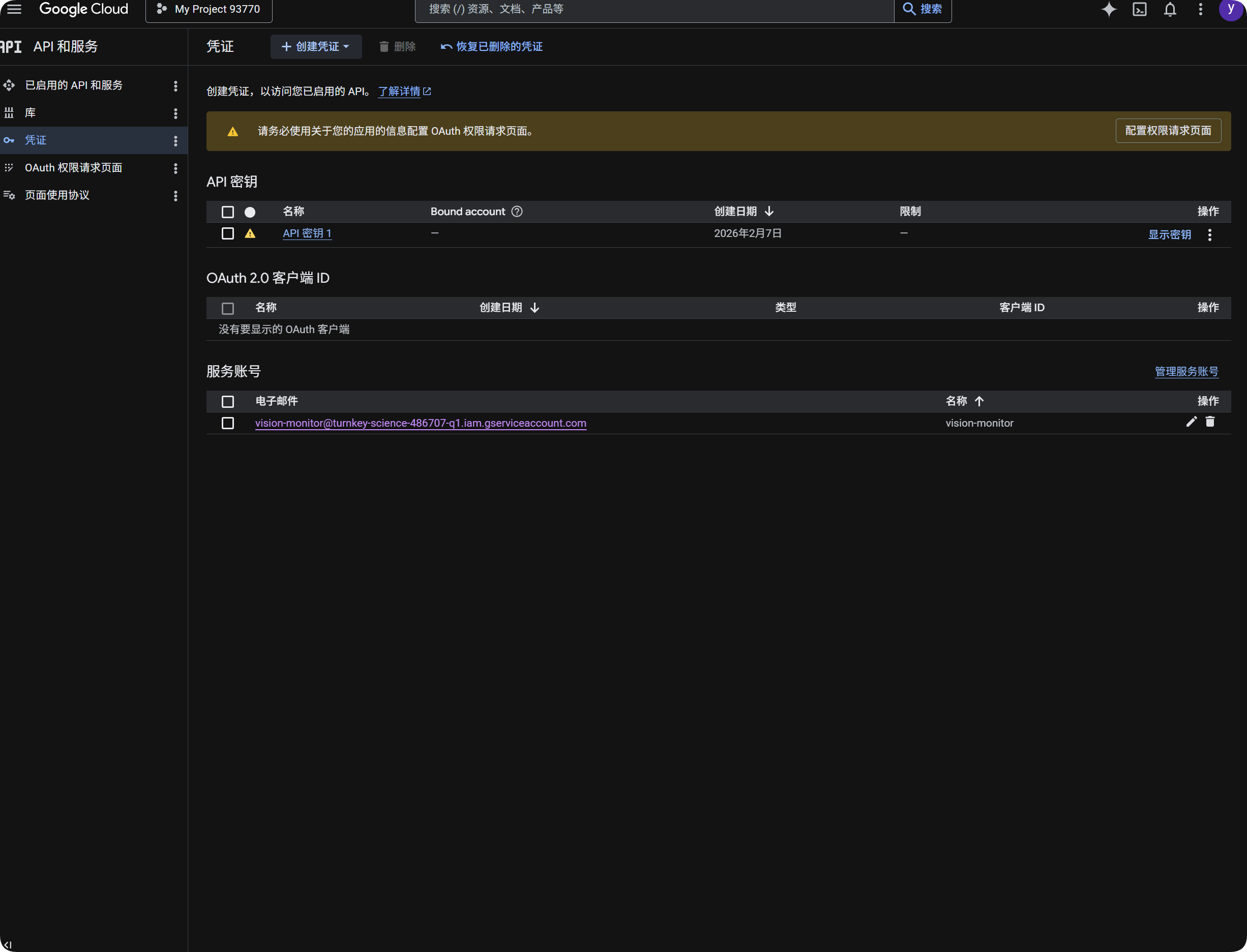
用谷歌做 OCR(文字识别)
操作顺序如下:
- 打开
Google Cloud Console(谷歌云控制台)。 - 进入
API 和服务(API 和服务)。 - 打开
库(库),搜索并启用Cloud Vision API(云视觉接口)。 - 回到
凭证(凭证)。 - 点击创建凭证,创建
API Key(接口密钥)。 - 点开这个
API Key(接口密钥),复制密钥内容。 - 回到图床后台,把密钥粘贴到
Google Vision API Key(谷歌视觉接口密钥)里。 - 点击保存。
这样就可以在 OCR(文字识别)弹窗里选择谷歌 Google Vision(谷歌视觉识别)来识别图片。
查询谷歌使用次数
查询额度不是识别必需项。
它只是用来查看谷歌 Google Vision(谷歌视觉识别)最近 30 天大概用了多少次。
操作顺序如下:
- 在
Google Cloud Console(谷歌云控制台)进入IAM 和管理(身份和权限管理)。 - 打开
服务账号(服务账号)。 - 创建一个服务账号,例如
vision-monitor(视觉用量监控)。 - 给这个服务账号添加
Monitoring Viewer(监控查看者)角色。 - 进入服务账号详情,创建密钥。
- 密钥类型选择
JSON(账号配置文件)。 - 下载生成的
JSON(账号配置文件)。 - 回到图床后台,在服务账号
JSON(可选)这里点击导入。 - 导入成功后,再点击查询额度。
导入成功后,后台会显示这个服务账号所属的项目名。
点查询额度时,系统会读取谷歌监控数据,然后显示这个月已经调用了多少次。
简单理解就是:
| 内容 | 作用 |
|---|---|
Google Vision API Key(谷歌视觉接口密钥) | 用来真正识别图片。 |
服务账号 JSON(账号配置文件) | 用来查询谷歌接口用了多少次。 |
Monitoring Viewer(监控查看者)角色 | 让服务账号可以读取用量数据。 |
获取百度飞桨令牌
百度飞桨 PaddleOCR(飞桨文字识别)需要先拿到访问令牌。
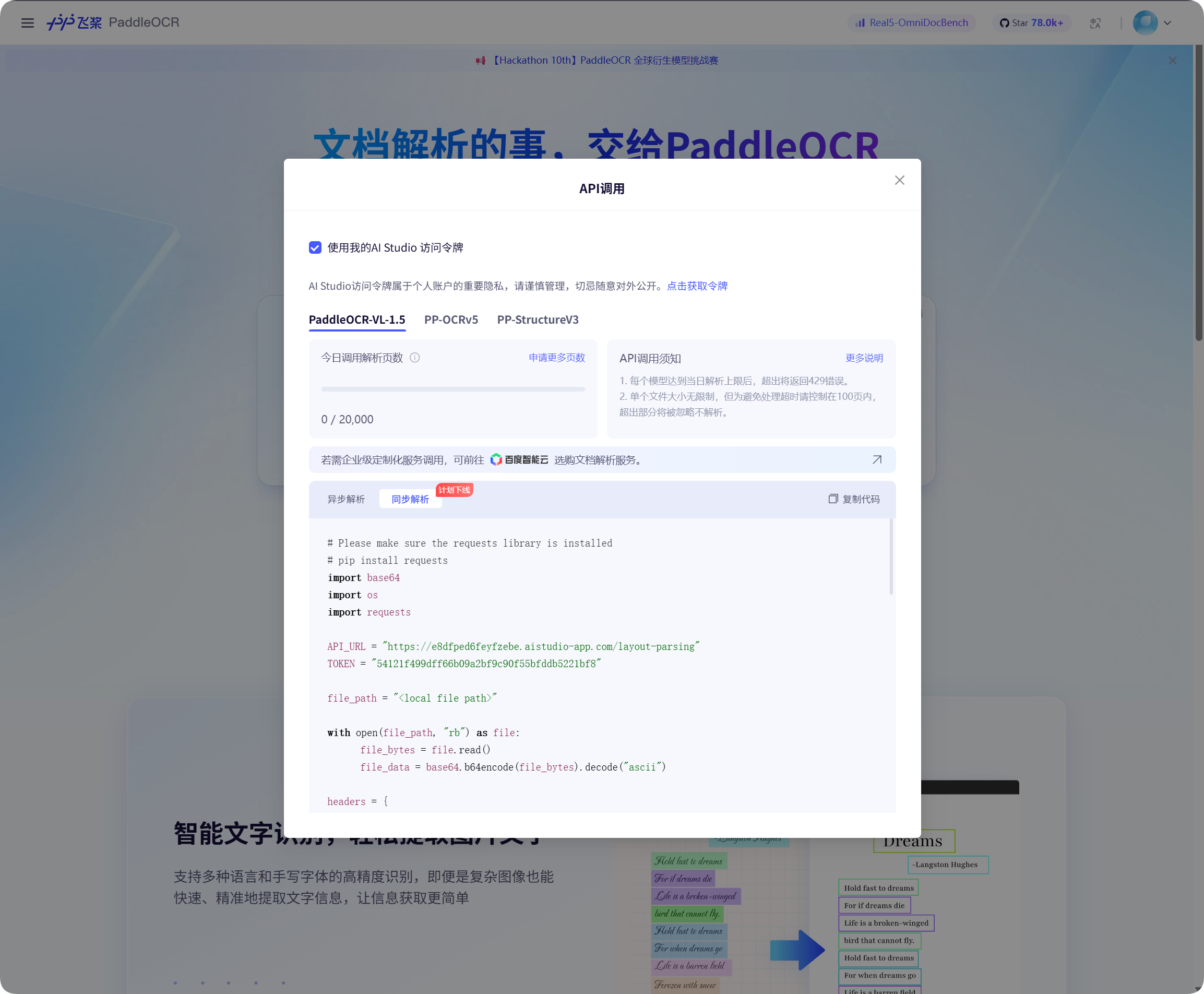
在百度飞桨页面里打开 API(接口)调用窗口,点击获取令牌,然后复制令牌内容。
回到图床后台,把令牌粘贴到 PaddleOCR Token(飞桨访问令牌)里保存即可。
开始识别
在文件管理里选中一个图片或文档截图,点击 OCR(文字识别)按钮。
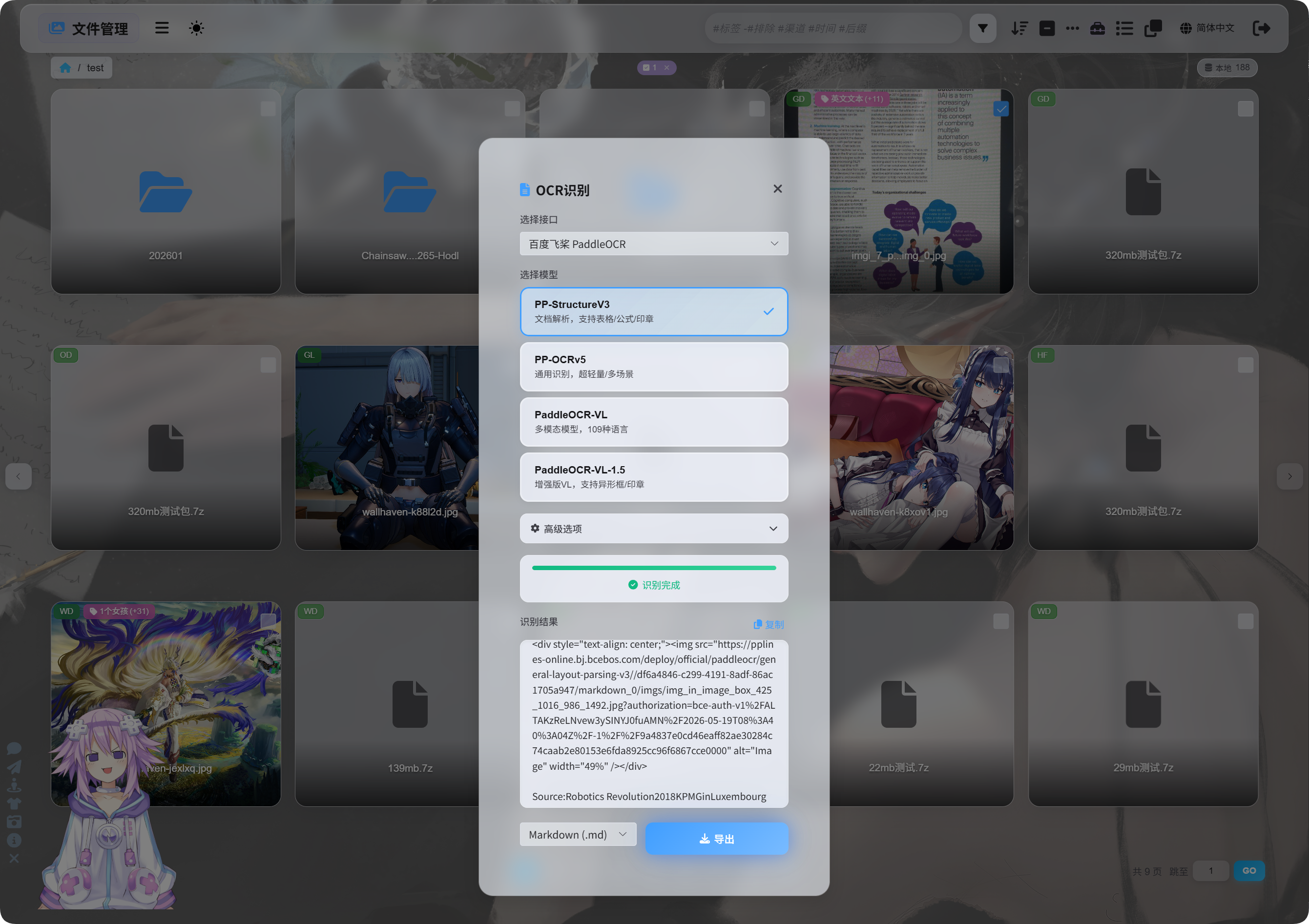
弹窗里可以选择识别接口和识别模型。
百度飞桨 PaddleOCR(飞桨文字识别)常用模型可以这样选:
| 模型 | 适合场景 |
|---|---|
PP-StructureV3(结构化文档识别) | 推荐默认使用,适合文档、表格、公式、印章、图文混排。 |
PP-OCRv5(通用文字识别) | 适合简单图片、普通文字、轻量识别。 |
PaddleOCR-VL(视觉语言模型) | 适合多语言、复杂图片、图表类内容。 |
PaddleOCR-VL-1.5(增强视觉语言模型) | 适合更复杂的文档页面和版面恢复。 |
不确定选哪个时,先用 PP-StructureV3(结构化文档识别)即可。
高级选项
识别弹窗里有高级选项,常用理解如下:
| 选项 | 说明 |
|---|---|
| 方向校正 | 图片拍歪、旋转时可以打开。 |
| 文档展平 | 拍照文档有弯曲、倾斜时可以打开。 |
| 版面检测 | 想保留标题、段落、表格、图片结构时建议打开。 |
| 图表识别 | 图片里有图表、复杂结构时再打开。 |
美化 Markdown(Markdown 文档) | 导出 Markdown(Markdown 文档)时更容易阅读。 |
普通截图可以少开选项,文档扫描件可以多开一些。
查看识别结果
识别完成后,弹窗里会显示识别结果。
可以直接复制,也可以选择导出格式后点击导出。

如果识别的是文档页面,PDF(PDF 文档)导出后可以保留页面效果,并且文字可以搜索。
这类结果适合保存原始版面,后面查找内容也方便。
导出格式怎么选
| 导出格式 | 适合场景 |
|---|---|
Markdown (.md)(Markdown 文档) | 适合整理笔记、复制到文档系统、后续继续编辑。 |
PDF (.pdf)(PDF 文档) | 适合保留页面效果,保存扫描件识别结果。 |
Word (.docx)(Word 文档) | 适合继续排版、修改文字、交给别人编辑。 |
| 全部导出 | 同时保存多种格式和原图,适合重要文件归档。 |
如果只是要文字,导出 Markdown(Markdown 文档)最轻。
如果还要页面效果,导出 PDF(PDF 文档)或 Word(Word 文档)更合适。
Word(Word 文档)效果
导出 Word(Word 文档)后,可以用办公软件打开继续编辑。
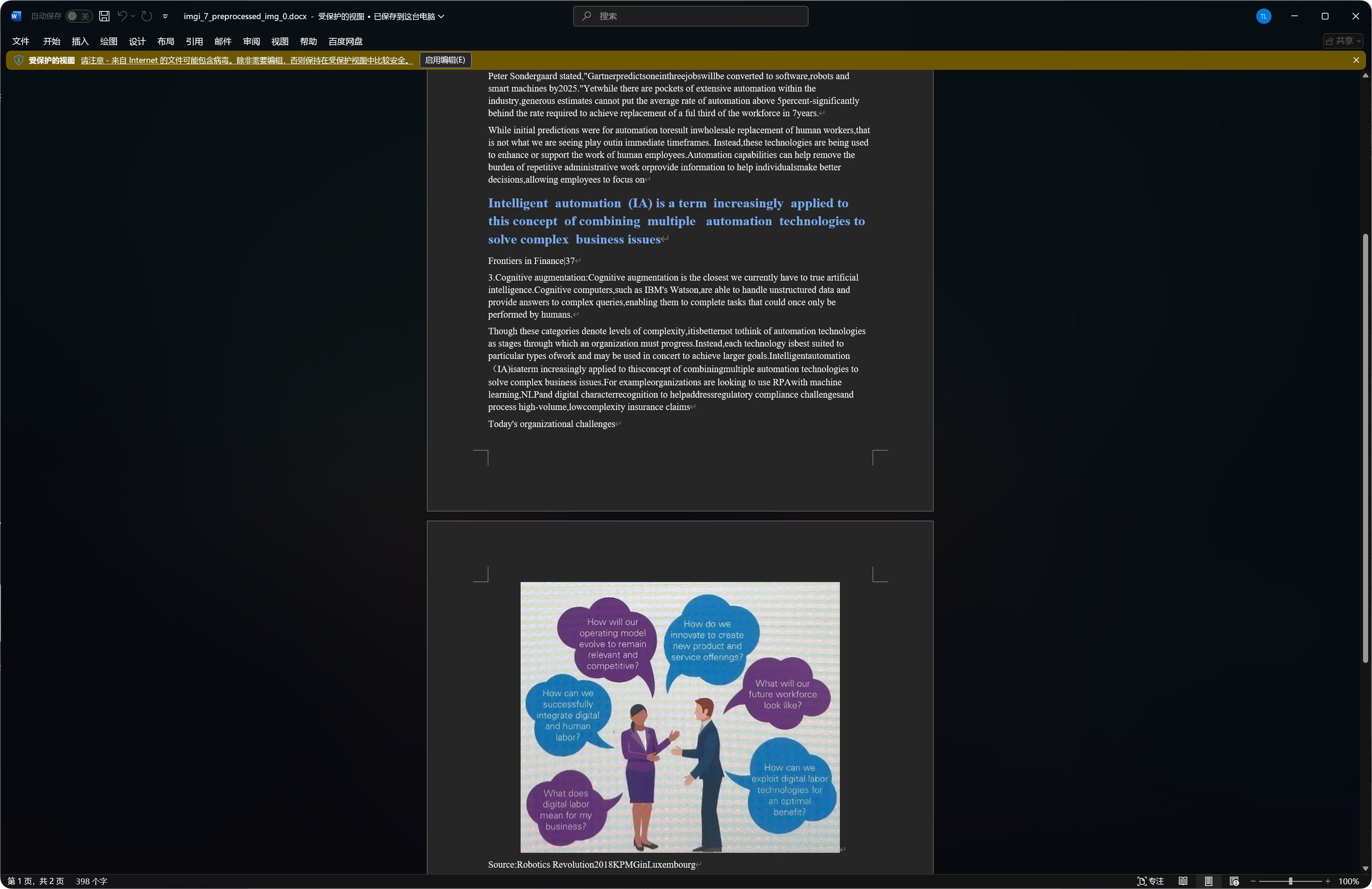
有些文档会把识别到的图片、标题、段落一起放进 Word(Word 文档)里。
识别效果和原图清晰度、模型选择、文档复杂度都有关系。
哪些文件更适合识别
| 文件类型 | 建议 |
|---|---|
| 清晰截图 | 直接识别即可。 |
| 扫描件 | 优先用 PP-StructureV3(结构化文档识别)。 |
| 拍照文档 | 可以打开方向校正、文档展平。 |
| 表格/公式/印章 | 优先用结构化模型。 |
| 普通短文字图片 | PP-OCRv5(通用文字识别)就够用。 |
图片越清晰、文字越端正,识别结果通常越好。
常见情况
| 情况 | 说明 |
|---|---|
| 识别失败 | 先检查对应服务的令牌或密钥有没有保存。 |
| 识别很慢 | 文档越复杂、图片越大,等待时间越长。 |
| 表格不完整 | 可以换结构化模型重新识别。 |
| 文字有错字 | 原图模糊、反光、倾斜时更容易出错,可以换更清晰的图片。 |
Word(Word 文档)里图片较多 | 结构化模型会保留部分识别图片,这是正常情况。 |
谷歌查询额度失败
先检查三件事:
- 是否已经导入服务账号
JSON(账号配置文件)。 - 服务账号是否有
Monitoring Viewer(监控查看者)角色。 - 当前项目是否已经启用
Cloud Vision API(云视觉接口)。
如果只是识别图片,不查询次数,可以先不管服务账号 JSON(账号配置文件),只填 Google Vision API Key(谷歌视觉接口密钥)就行。
简单流程
text
打开系统配置
-> 进入其他设置
-> 填写 OCR 服务凭据
-> 保存
-> 回到文件管理
-> 选中文件并点击 OCR 识别
-> 选择模型
-> 等待识别完成
-> 复制结果或导出 Markdown / PDF / Word