OCR
OCR извлекает текст из изображений, сканов и скриншотов документов.
После распознавания можно скопировать результат, экспортировать его как Markdown, PDF или Word, либо упаковать несколько форматов вместе для скачивания.
Что умеет OCR
| Возможность | Описание |
|---|---|
| Распознавание текста на изображении | Извлекает текст из изображений, скриншотов и сканов. |
| Распознавание структуры документа | Лучше подходит для таблиц, формул, печатей и смешанных text-image layouts. |
| Несколько сервисов | Поддерживает Baidu PaddleOCR, Microsoft Azure Vision и Google Vision. |
| Копирование результатов | Копирует распознанный текст после обработки. |
| Экспорт файлов | Экспортирует Markdown, PDF и Word. |
| Batch packaging | После распознавания нескольких файлов можно скачать результаты пакетом. |
Сначала настройте OCR-сервисы
Откройте:
text
System Settings -> Other Settings -> OCR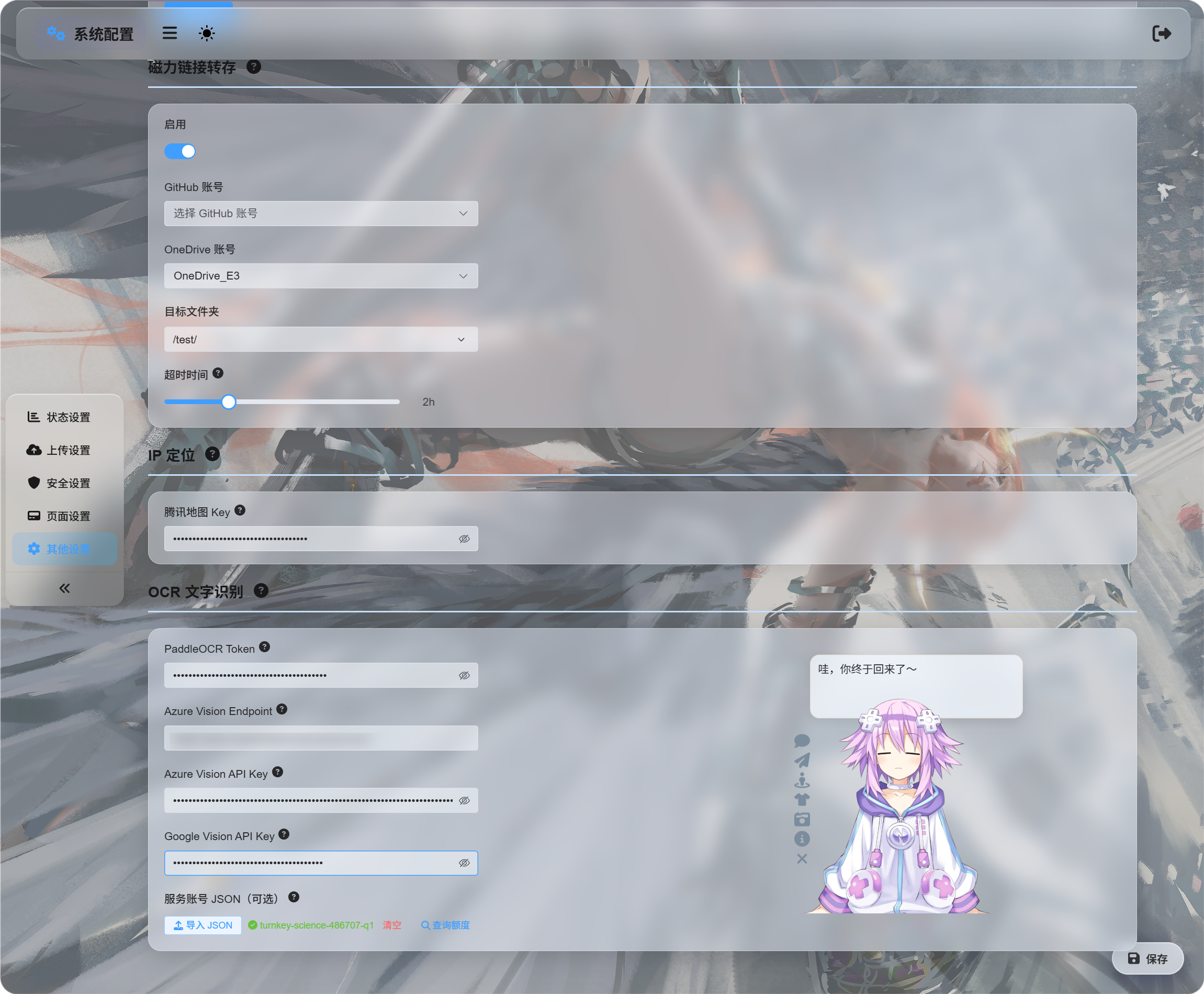
Заполните credentials для сервисов, которые хотите использовать:
| Сервис | Что ввести | Лучше всего подходит для |
|---|---|---|
| Baidu PaddleOCR | PaddleOCR Token | Рекомендуемый первый выбор. Хорошо работает с документами, изображениями, таблицами и смешанными layout. |
| Microsoft Azure Vision | Azure Vision Endpoint и Azure Vision API Key | Полезно, если вы уже используете облачные сервисы Microsoft. |
| Google Vision | Google Vision API Key. Service account JSON используется только для quota query. | Полезно, если вы используете Google Cloud. |
После заполнения credentials сохраните настройки.
Для первого теста можно настроить только один сервис. Все три не нужны.
Настройка Google Vision
Настройка Google состоит из двух частей:
| Цель | Требование |
|---|---|
| Использовать OCR | Включить Cloud Vision API, затем создать API Key. |
| Запрашивать usage | Создать service account, выдать Monitoring Viewer, затем скачать service account JSON. |
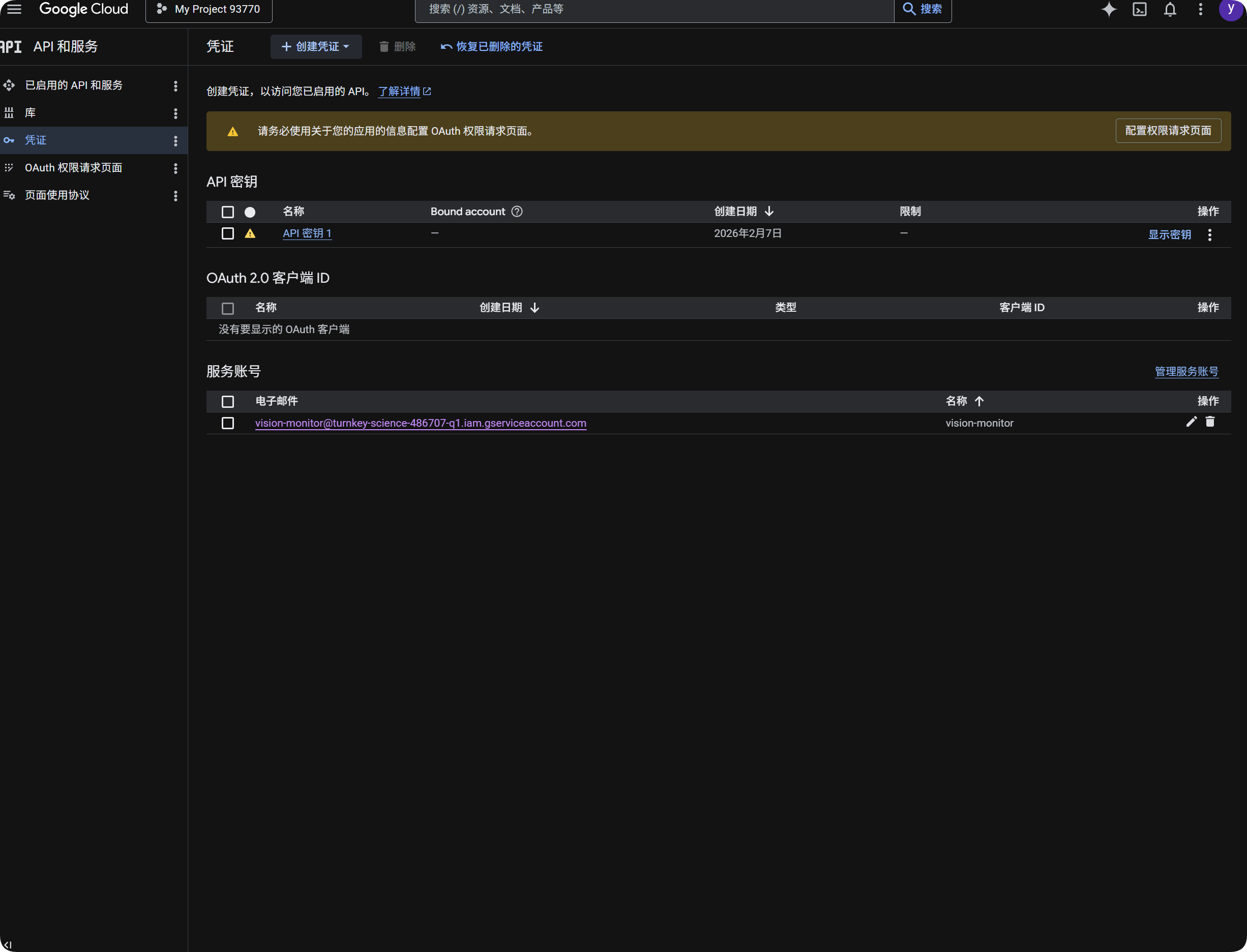
Использование Google для OCR
- Откройте Google Cloud Console.
- Перейдите в
APIs & Services. - Откройте
Library, найдитеCloud Vision APIи включите его. - Вернитесь в
Credentials. - Создайте
API Key. - Откройте API Key и скопируйте его.
- Вставьте его в
Google Vision API Keyв ImgBed. - Сохраните.
После этого в OCR-диалоге можно выбрать Google Vision.
Запрос usage Google
Quota query не нужен для самого распознавания.
Он только примерно показывает, сколько вызовов Google Vision было использовано за последние 30 дней.
- В Google Cloud Console откройте
IAM & Admin. - Откройте
Service Accounts. - Создайте service account, например
vision-monitor. - Выдайте ему роль
Monitoring Viewer. - Откройте детали service account и создайте key.
- Выберите
JSON. - Скачайте созданный JSON-файл.
- Вернитесь в ImgBed и импортируйте его в service account
JSON(необязательно). - После успешного импорта нажмите quota query.
После импорта ImgBed показывает project name, которому принадлежит service account. При запросе usage ImgBed читает Google monitoring data и показывает количество вызовов за текущий месяц.
Коротко:
| Элемент | Назначение |
|---|---|
Google Vision API Key | Выполняет OCR recognition. |
Service account JSON | Запрашивает, сколько вызовов Google Vision использовано. |
Monitoring Viewer role | Позволяет service account читать usage data. |
Получение Baidu PaddleOCR Token
Baidu PaddleOCR требует access token.
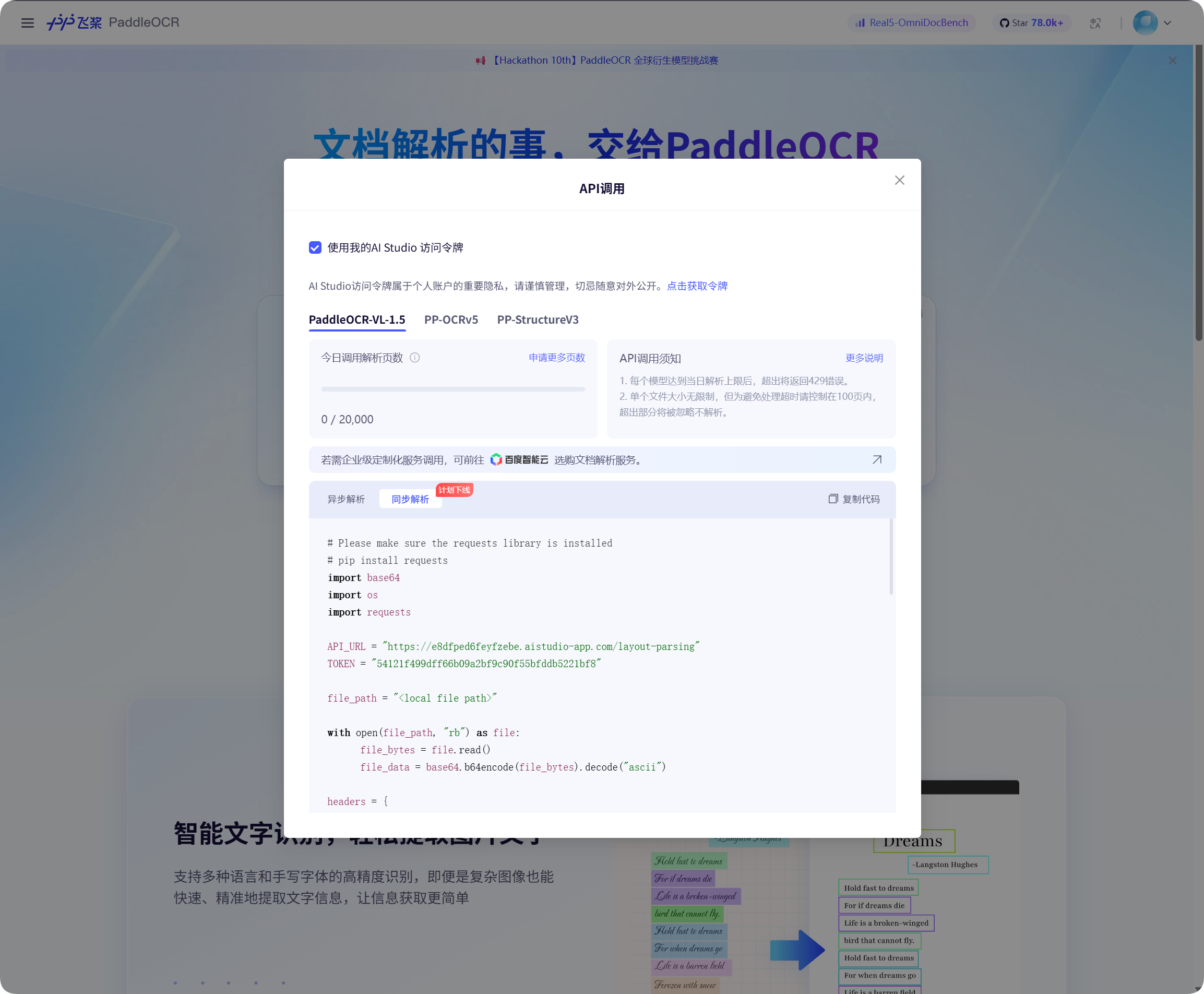
Откройте окно вызова API на странице Baidu PaddleOCR, нажмите получение token и скопируйте его.
Вернитесь в ImgBed, вставьте его в PaddleOCR Token и сохраните.
Запуск распознавания
В File Management выберите изображение или скриншот документа и нажмите OCR.
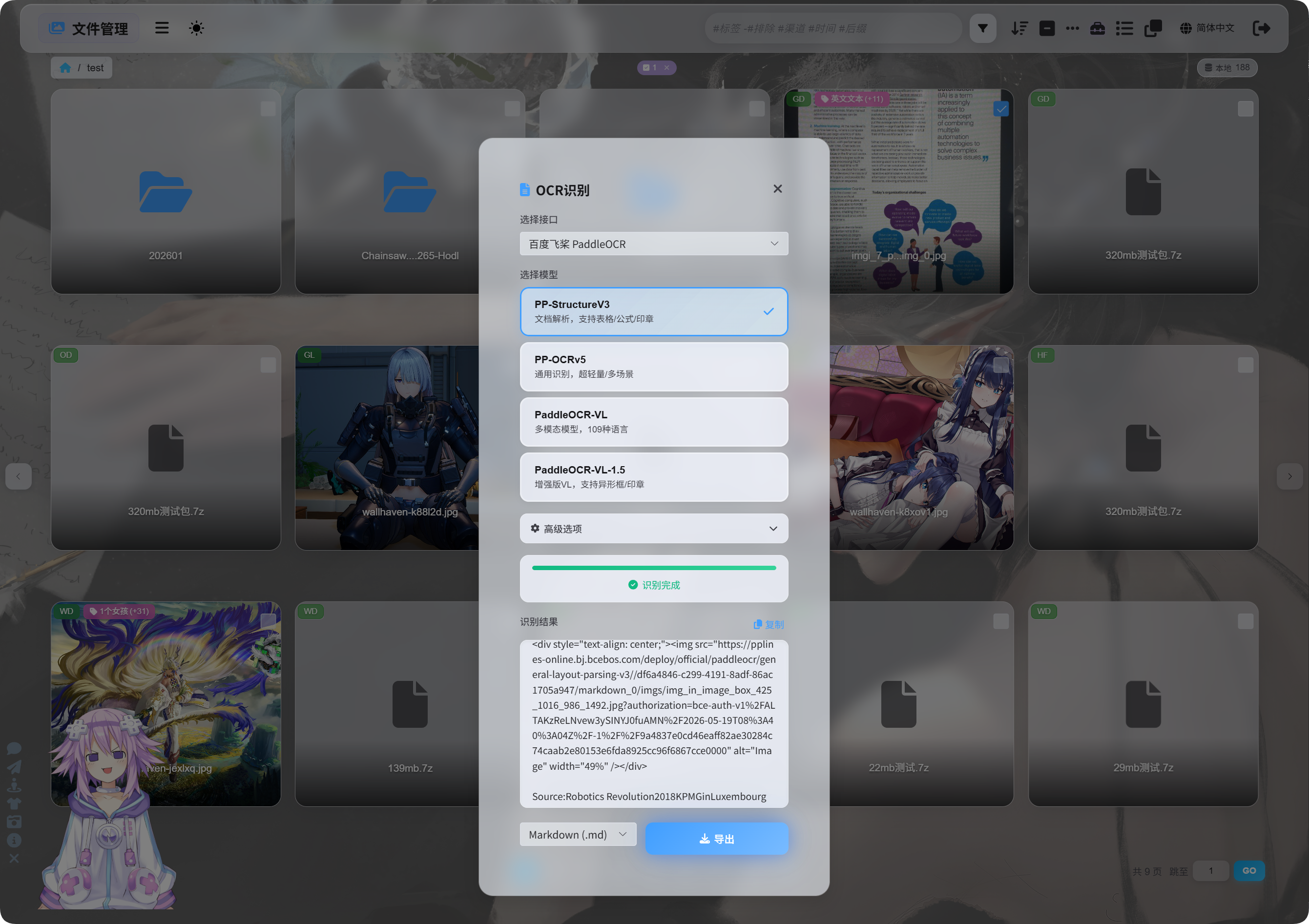
В диалоге выберите service и model.
Распространенные PaddleOCR models:
| Model | Лучше всего подходит для |
|---|---|
PP-StructureV3 | Рекомендуется по умолчанию. Хорошо для документов, таблиц, формул, печатей и смешанных layout. |
PP-OCRv5 | Простые изображения, обычный текст и легкое распознавание. |
PaddleOCR-VL | Многоязычные, сложные изображения и chart-like content. |
PaddleOCR-VL-1.5 | Более сложные страницы документов и восстановление layout. |
Если не уверены, начните с PP-StructureV3.
Advanced Options
| Опция | Описание |
|---|---|
| Orientation correction | Используйте, когда изображение повернуто или перекошено. |
| Document flattening | Для сфотографированных документов с изгибом или наклоном. |
| Layout detection | Когда нужно сохранить headings, paragraphs, tables и структуру изображений. |
| Chart recognition | Когда изображение содержит charts или сложные структуры. |
Beautify Markdown | Делает экспортированный Markdown удобнее для чтения. |
Для обычных скриншотов оставляйте минимум опций. Для сканов документов включайте больше document-related options.
Просмотр результатов
После завершения распознавания диалог показывает результат.
Его можно скопировать напрямую или выбрать форматы экспорта.

Для страниц документов экспортированный PDF может сохранять внешний вид страницы и при этом оставлять текст пригодным для поиска. Это удобно для архивирования сканов и дальнейшего поиска содержимого.
Выбор формата экспорта
| Формат | Лучше всего для |
|---|---|
Markdown (.md) | Заметки, документационные системы и дальнейшее редактирование. |
PDF (.pdf) | Сохранение внешнего вида страницы и результатов сканированных документов. |
Word (.docx) | Дальнейшее редактирование layout, изменение текста и передача другим. |
| Export all | Сохраняет несколько форматов и исходное изображение, подходит для важных архивов. |
Если нужен только текст, экспортируйте Markdown.
Если важен внешний вид страницы, используйте PDF или Word.
Word Output
Экспортированные Word-документы можно открывать и редактировать в office software.
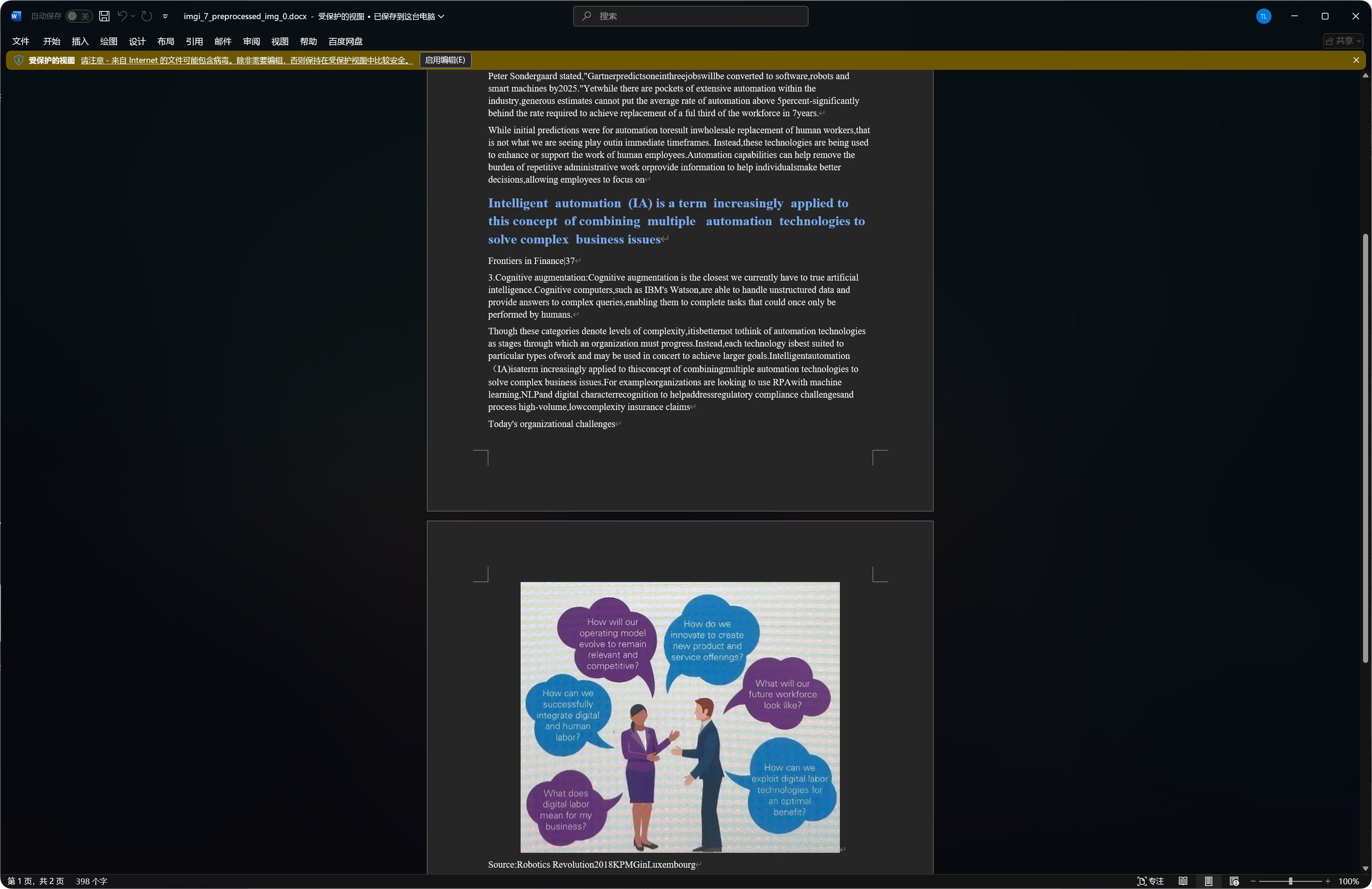
Некоторые документы содержат распознанные изображения, headings и paragraphs в Word output.
Качество распознавания зависит от четкости оригинала, выбора model и сложности документа.
Лучшие типы файлов для OCR
| Тип файла | Рекомендация |
|---|---|
| Четкие скриншоты | Распознавать напрямую. |
| Сканы | Лучше PP-StructureV3. |
| Сфотографированные документы | Включить orientation correction и document flattening. |
| Таблицы, формулы, печати | Лучше structured models. |
| Простые короткие текстовые изображения | PP-OCRv5 обычно достаточно. |
Более четкие изображения с ровным текстом обычно дают лучший результат.
Типичные случаи
| Случай | Значение |
|---|---|
| Recognition fails | Проверьте, сохранен ли service token или key. |
| Recognition is slow | Сложные документы и большие изображения требуют больше времени. |
| Table is incomplete | Попробуйте structured model. |
| Text has mistakes | Размытие, блики и перекос увеличивают ошибки. Попробуйте более четкое изображение. |
| Word output contains many images | Structured models могут сохранять часть распознанных изображений. Это нормально. |
Google Quota Query Fails
Проверьте:
- Service account
JSONимпортирован. - Service account имеет роль
Monitoring Viewer. Cloud Vision APIвключен для проекта.
Если нужен только OCR, а не usage query, service account JSON можно не использовать и заполнить только Google Vision API Key.
Короткий сценарий
text
Открыть System Settings
-> Открыть Other Settings
-> Заполнить OCR service credentials
-> Сохранить
-> Вернуться в File Management
-> Выбрать файл и нажать OCR
-> Выбрать model
-> Дождаться recognition
-> Скопировать результат или экспортировать Markdown / PDF / Word