OCR
OCR images، scans، اور document screenshots سے text extract کرتا ہے۔
recognition کے بعد آپ result copy کر سکتے ہیں، اسے Markdown، PDF، یا Word کے طور پر export کر سکتے ہیں، یا multiple formats کو ایک package بنا کر download کر سکتے ہیں۔
OCR کیا کر سکتا ہے
| Feature | Description |
|---|---|
| Image text recognition | images، screenshots، اور scans سے text extract کرتا ہے۔ |
| Document layout recognition | tables، formulas، stamps، اور mixed text-image layouts کے لیے بہتر۔ |
| Multiple services | Baidu PaddleOCR، Microsoft Azure Vision، اور Google Vision support کرتا ہے۔ |
| Copy results | processing کے بعد recognized text copy کریں۔ |
| Export files | Markdown، PDF، اور Word export کریں۔ |
| Batch packaging | multiple files recognize ہونے کے بعد results کو package کے طور پر download کریں۔ |
پہلے OCR Services Configure کریں
کھولیں:
text
System Settings -> Other Settings -> OCR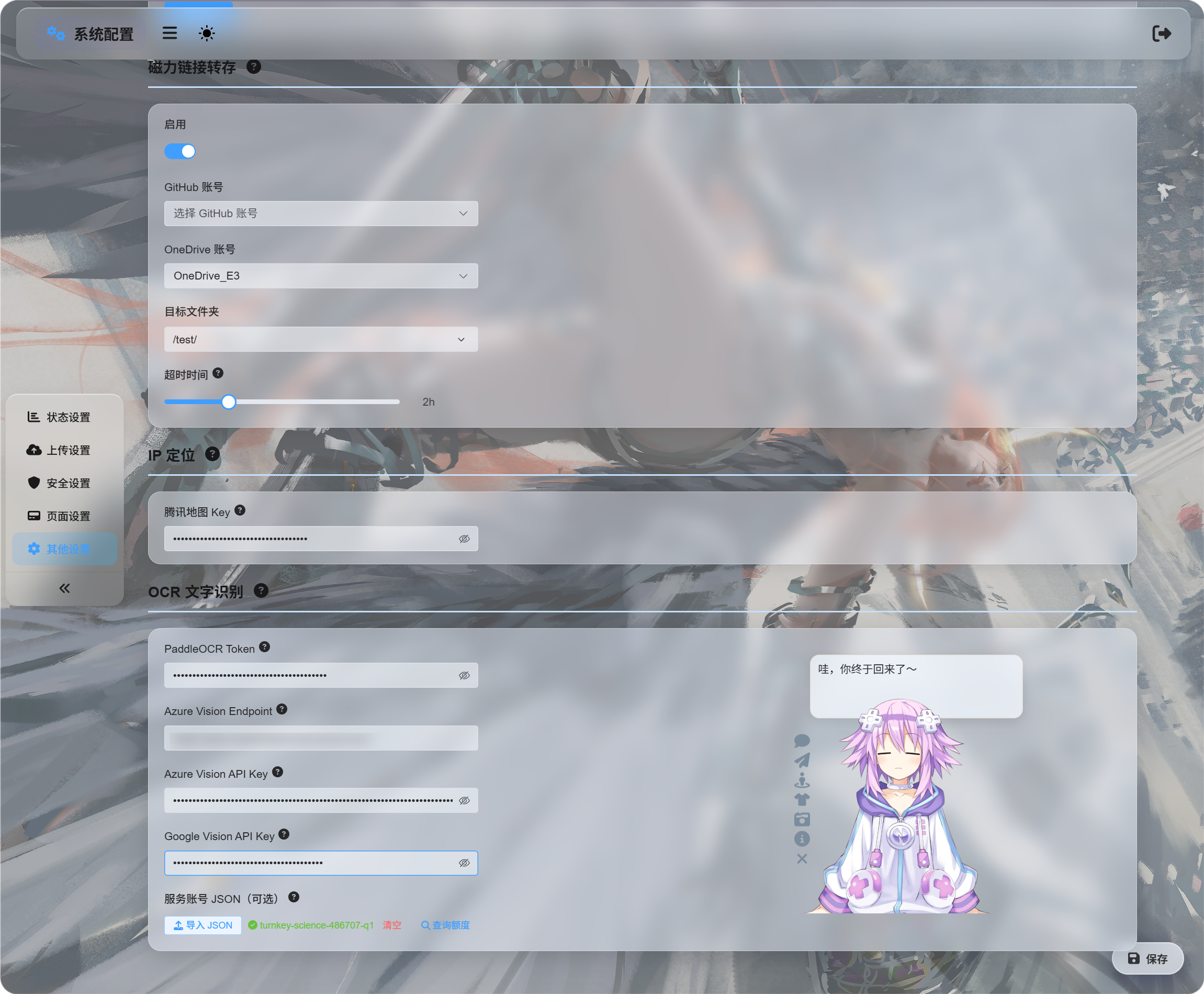
جن services کو استعمال کرنا ہے ان کے credentials بھریں:
| Service | What To Enter | Best For |
|---|---|---|
| Baidu PaddleOCR | PaddleOCR Token | recommended first choice۔ documents، images، tables، اور mixed layouts کے لیے اچھا۔ |
| Microsoft Azure Vision | Azure Vision Endpoint اور Azure Vision API Key | اگر آپ پہلے سے Microsoft cloud services استعمال کرتے ہیں تو useful۔ |
| Google Vision | Google Vision API Key۔ Service account JSON صرف quota query کے لیے استعمال ہوتا ہے۔ | اگر آپ Google Cloud services استعمال کرتے ہیں تو useful۔ |
credentials بھرنے کے بعد save کریں۔
initial testing کے لیے صرف ایک service configure کرنا کافی ہے۔ تینوں ضروری نہیں۔
Google Vision Setup
Google setup کے دو parts ہیں:
| Goal | Requirement |
|---|---|
| OCR استعمال کرنا | Cloud Vision API enable کریں، پھر API Key بنائیں۔ |
| usage query کرنا | service account بنائیں، Monitoring Viewer grant کریں، پھر service account JSON download کریں۔ |
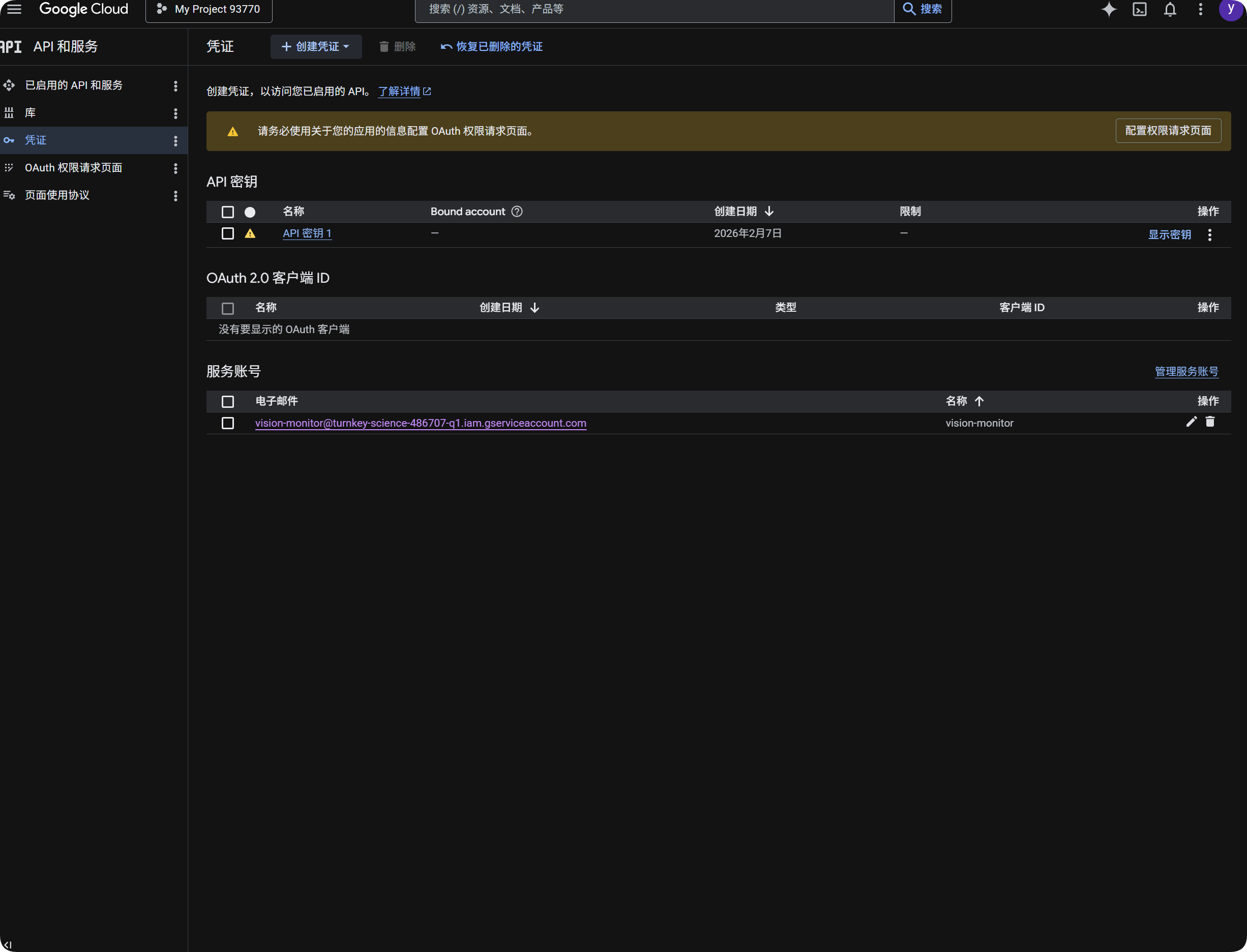
Google کو OCR کے لیے استعمال کرنا
- Google Cloud Console کھولیں۔
APIs & Servicesمیں جائیں۔Libraryکھولیں،Cloud Vision APIتلاش کریں، اور enable کریں۔Credentialsپر واپس جائیں۔API Keyبنائیں۔- API Key کھولیں اور copy کریں۔
- ImgBed میں
Google Vision API Keyمیں paste کریں۔ - Save کریں۔
اس کے بعد OCR dialog میں Google Vision منتخب کیا جا سکتا ہے۔
Google Usage Query
Quota query recognition کے لیے required نہیں۔
یہ صرف تقریباً دکھاتا ہے کہ پچھلے 30 دنوں میں Google Vision calls کتنی استعمال ہوئیں۔
- Google Cloud Console میں
IAM & Adminکھولیں۔ Service Accountsکھولیں۔- service account بنائیں، مثلاً
vision-monitor۔ - اسے
Monitoring Viewerrole دیں۔ - service account details کھولیں اور key بنائیں۔
JSONمنتخب کریں۔- generated JSON file download کریں۔
- ImgBed پر واپس آ کر اسے service account
JSONکے تحت import کریں (optional)۔ - import successful ہونے کے بعد quota query پر کلک کریں۔
import کے بعد ImgBed service account کے owning project کا نام دکھاتا ہے۔ usage query کرتے وقت ImgBed Google monitoring data پڑھ کر اس month کا call count دکھاتا ہے۔
مختصر:
| Item | Purpose |
|---|---|
Google Vision API Key | OCR recognition چلاتا ہے۔ |
Service account JSON | Google Vision calls کی usage query کرتا ہے۔ |
Monitoring Viewer role | service account کو usage data پڑھنے دیتا ہے۔ |
Baidu PaddleOCR Token حاصل کریں
Baidu PaddleOCR access token require کرتا ہے۔
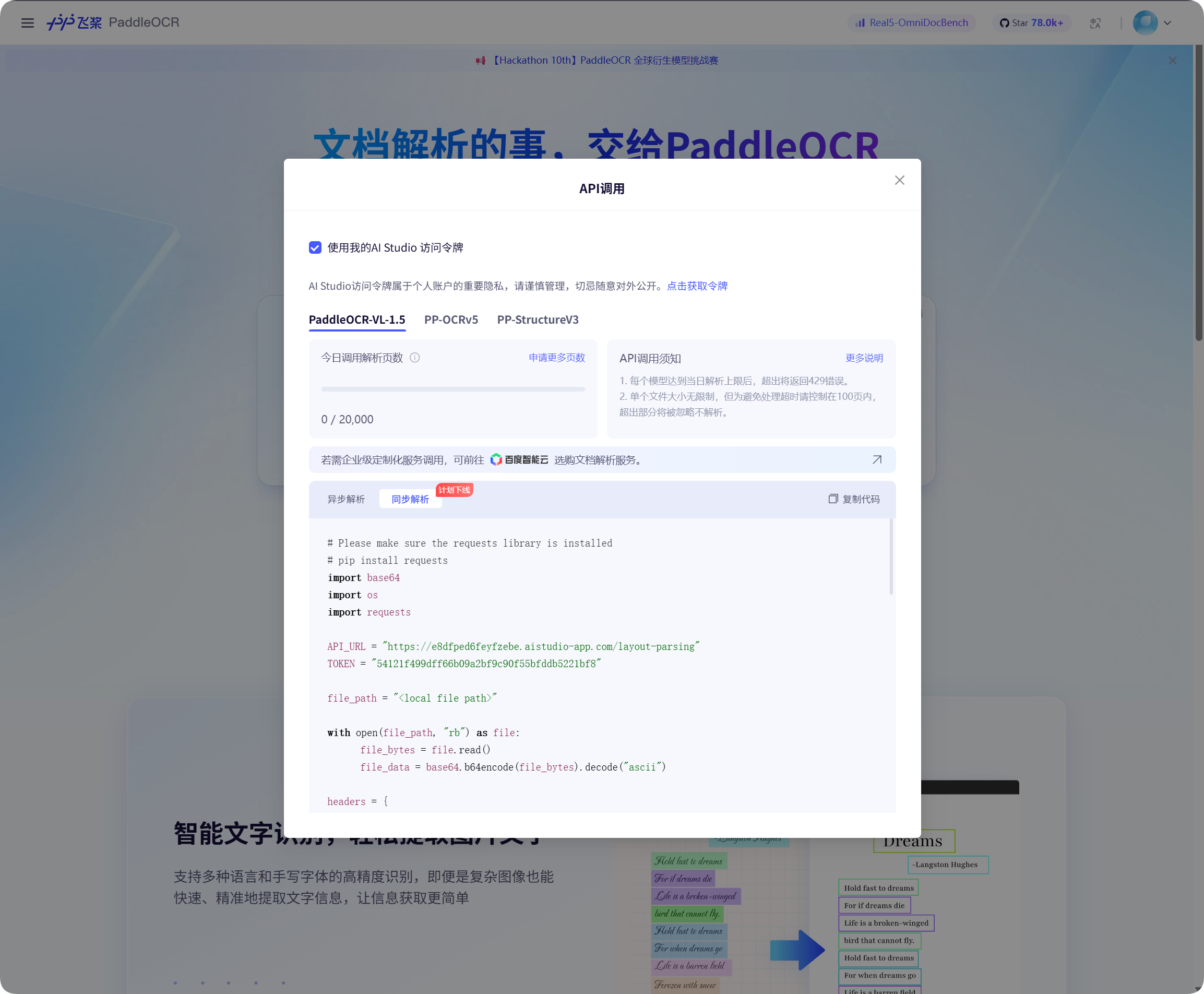
Baidu PaddleOCR page پر API call window کھولیں، token لینے کے لیے click کریں، پھر اسے copy کریں۔
ImgBed پر واپس آ کر PaddleOCR Token میں paste کریں اور save کریں۔
Recognition شروع کریں
File Management میں image یا document screenshot منتخب کریں اور OCR پر کلک کریں۔
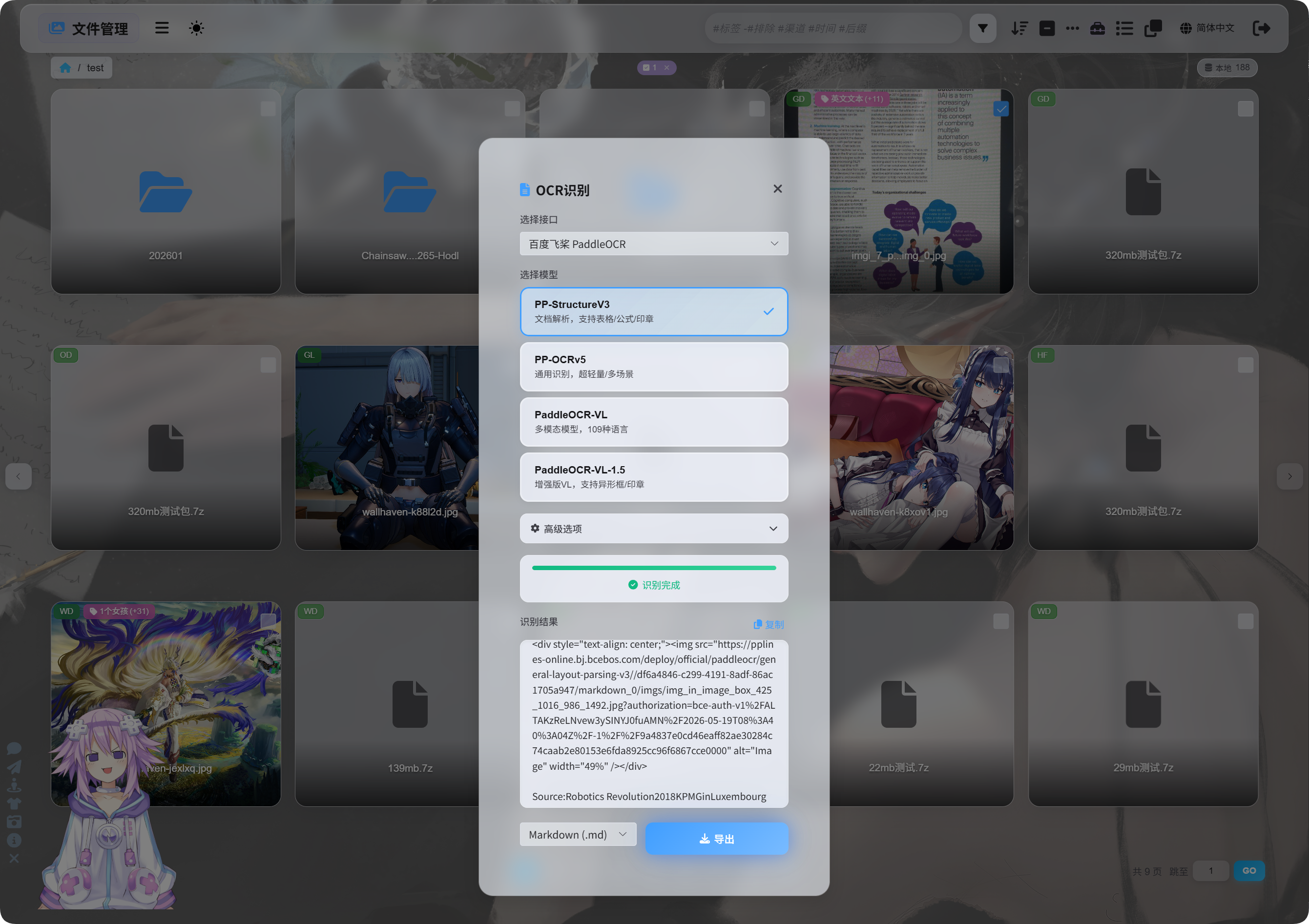
dialog میں recognition service اور model منتخب کریں۔
Common PaddleOCR model choices:
| Model | Best For |
|---|---|
PP-StructureV3 | recommended default۔ documents، tables، formulas، stamps، اور mixed layouts کے لیے اچھا۔ |
PP-OCRv5 | simple images، ordinary text، اور lightweight recognition۔ |
PaddleOCR-VL | multilingual، complex images، اور chart-like content۔ |
PaddleOCR-VL-1.5 | زیادہ complex document pages اور layout recovery۔ |
یقین نہ ہو تو PP-StructureV3 سے شروع کریں۔
Advanced Options
| Option | Description |
|---|---|
| Orientation correction | image rotated یا skewed ہو تو استعمال کریں۔ |
| Document flattening | photographed documents میں curvature یا tilt ہو تو استعمال کریں۔ |
| Layout detection | headings، paragraphs، tables، اور image structure preserve کرنا ہو تو استعمال کریں۔ |
| Chart recognition | image میں charts یا complex structures ہوں تو استعمال کریں۔ |
Beautify Markdown | exported Markdown کو زیادہ readable بناتا ہے۔ |
regular screenshots کے لیے options minimal رکھیں۔ document scans کے لیے document-related options زیادہ enable کریں۔
Results دیکھیں
recognition finish ہونے کے بعد dialog result دکھاتا ہے۔
آپ اسے directly copy کر سکتے ہیں یا export formats منتخب کر سکتے ہیں۔

document pages کے لیے exported PDF page appearance preserve کر سکتا ہے جبکہ text searchable رہتا ہے۔ یہ scans archive کرنے اور بعد میں content تلاش کرنے کے لیے useful ہے۔
Export Format منتخب کرنا
| Format | Best For |
|---|---|
Markdown (.md) | notes، documentation systems، اور later editing۔ |
PDF (.pdf) | page appearance اور scanned document results preserve کرنا۔ |
Word (.docx) | layout editing، text modification، اور others کو handoff۔ |
| Export all | multiple formats اور original image save کرتا ہے، important archives کے لیے مناسب۔ |
صرف text چاہیے ہو تو Markdown export کریں۔
page appearance چاہیے ہو تو PDF یا Word استعمال کریں۔
Word Output
exported Word documents office software میں open اور edit ہو سکتے ہیں۔
کچھ documents Word output میں recognized images، headings، اور paragraphs شامل کرتے ہیں۔
recognition quality original image clarity، model choice، اور document complexity پر depend کرتی ہے۔
OCR کے لیے بہترین File Types
| File Type | Recommendation |
|---|---|
| Clear screenshots | directly recognize کریں۔ |
| Scans | PP-StructureV3 کو ترجیح دیں۔ |
| Photographed documents | orientation correction اور document flattening enable کریں۔ |
| Tables, formulas, stamps | structured models کو ترجیح دیں۔ |
| Simple short text images | PP-OCRv5 عموماً کافی ہے۔ |
زیادہ clear images اور سیدھا text عموماً بہتر results دیتے ہیں۔
Common Cases
| Case | Meaning |
|---|---|
| Recognition fails | چیک کریں کہ service token یا key save ہو چکی ہے۔ |
| Recognition slow ہے | complex documents اور large images زیادہ وقت لیتے ہیں۔ |
| Table incomplete ہے | structured model try کریں۔ |
| Text میں mistakes ہیں | blur، glare، اور skew errors بڑھاتے ہیں۔ clearer image try کریں۔ |
| Word output میں بہت سی images ہیں | structured models کچھ recognized images preserve کر سکتے ہیں۔ یہ normal ہے۔ |
Google Quota Query Fail ہوتی ہے
چیک کریں:
- Service account
JSONimport ہو چکا ہے۔ - service account کے پاس
Monitoring Viewerrole ہے۔ - project کے لیے
Cloud Vision APIenabled ہے۔
اگر آپ کو صرف OCR چاہیے اور usage query نہیں، تو service account JSON ignore کر کے صرف Google Vision API Key بھر سکتے ہیں۔
Quick Flow
text
System Settings کھولیں
-> Other Settings کھولیں
-> OCR service credentials بھریں
-> Save
-> File Management پر واپس جائیں
-> file منتخب کریں اور OCR پر کلک کریں
-> model منتخب کریں
-> recognition کا انتظار کریں
-> results copy کریں یا Markdown / PDF / Word export کریں